hive基本使用
由于最近项目需要和大数据对接,需要了解一下数仓的基本知识,所以记录一下hive的基础原理和使用
hive简介
Hive是一种用类SQL语句来协助读写、管理那些存储在分布式存储系统上大数据集的数据仓库软件
hive的特点:
- 通过类SQL来分析大数据,而避免了写MapReduce程序来分析数据,这样使得分析数据更容易
- 数据是存储在HDFS上的,Hive本身并不提供数据的存储功能
- Hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)
- 数据存储方面:它能够存储很大的数据集,并且对数据完整性、格式要求并不严格
- 数据处理方面:因为Hive语句最终会生成MapReduce任务去计算,所以不适用于实时计算的场景,它适用于离线分析
整体架构
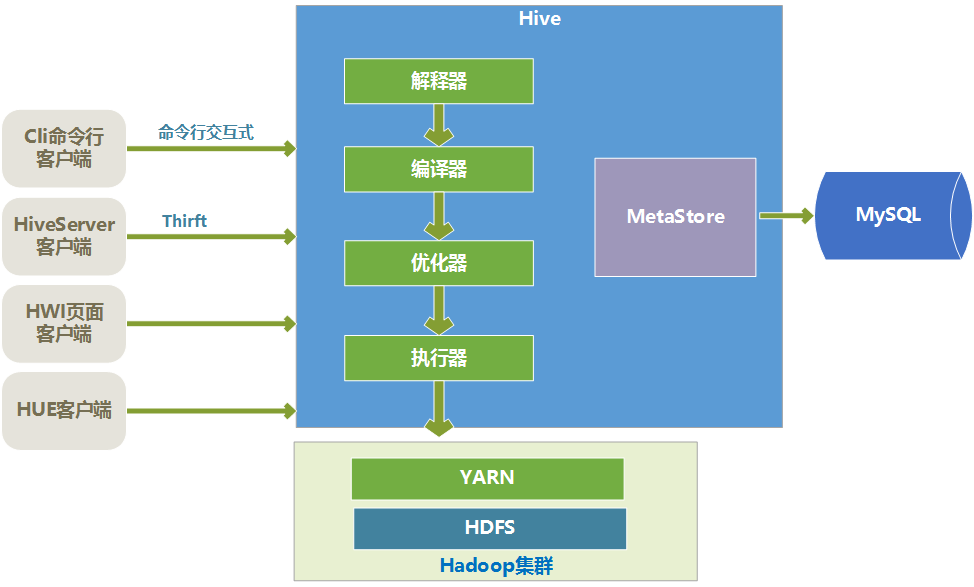
驱动引擎
Hive的核心是驱动引擎,驱动引擎由四部分组成:
- 解释器:解释器的作用是将HiveSQL语句转换为语法树(AST)
- 编译器:编译器是将语法树编译为逻辑执行计划
- 优化器:优化器是对逻辑执行计划进行优化
- 执行器:执行器是调用底层的运行框架执行逻辑执行计划
底层存储和执行流程
Hive的数据是存储在HDFS上的。Hive中的库和表可以看作是对HDFS上数据做的一个映射。所以Hive必须是运行在一个Hadoop集群上的
Hive中的执行器,是将最终要执行的MapReduce程序放到YARN上以一系列Job的方式去执行
Hive元数据的存储结构
Hive的元数据是一般是存储在MySQL这种关系型数据库上的,Hive和MySQL之间通过MetaStore服务交互
| 元数据项 | 说明 |
|---|---|
| Owner | 库、表的所属者 |
| LastAccessTime | 最后修改时间 |
| Table Type | 表类型(内部表、外部表) |
| CreateTime | 创建时间 |
| Location | 存储位置 |
Hive客户端
Hive的客户端种类:
- cli命令行客户端:采用交互窗口,用hive命令行和Hive进行通信。
- HiveServer2客户端:用Thrift协议进行通信,Thrift是不同语言之间的转换器,是连接不同语言程序间的协议,通过JDBC或者ODBC去访问Hive
- HUE客户端:通过Web页面来和Hive进行交互,使用的比较多
Hive基本数据类型
Hive支持关系型数据中大多数基本数据类型,同时Hive中也有特有的三种复杂类型。
| 数据类型 | 长度 | 备注 |
|---|---|---|
| Tinyint | 1字节的有符号整数 | -128~127 |
| SmallInt | 1个字节的有符号整数 | -32768~32767 |
| Int | 4个字节的有符号整数 | -2147483648 ~ 2147483647 |
| BigInt | 8个字节的有符号整数 | |
| Boolean | 布尔类型,true或者false | true、false |
| Float | 单精度浮点数 | |
| Double | 双精度浮点数 | |
| String | 字符串 | |
| TimeStamp | 整数 支持Unix timestamp,可以达到纳秒精度 | |
| Binary | 字节数组 | |
| Date | 日期 0000-01-01 ~ 9999-12-31,常用String代替 |
DDL操作(库和表的定义)
库操作
创建一个数据库会在HDFS上创建一个目录,Hive里数据库的概念类似于程序中的命名空间,用数据库来组织表,在大量Hive的情况下,用数据库来分开可以避免表名冲突。Hive默认的数据库是default。
hive> create database if not exists user_db;
Describe 命令来查看数据库定义,包括:数据库名称、数据库在HDFS目录、HDFS用户名称。
hive> describe database user_db;
数据库名称 数据库在HDFS的目录 HDFS用户名称
删除、切换数据库与mysql命令一样(drop、use)
创建表
创建表一般有几种方式:
- create table 方式
- create table as select 方式:根据查询的结果自动创建表,并将查询结果数据插入新建的表中
- create table like tablename1 方式:是克隆表,只复制tablename1表的结构
外部表
外部表是没有被hive完全控制的表,当表删除后,数据不会被删除。
1 | |
创建分区表
Hive查询一般是扫描整个目录,但是有时候我们关心的数据只是集中在某一部分数据上,比如我们一个Hive查询,往往是只是查询某一天的数据,这样的情况下,可以使用分区表来优化,一天是一个分区,查询时候,Hive只扫描指定天分区的数据
普通表和分区表的区别在于:一个Hive表在HDFS上是有一个对应的目录来存储数据,普通表的数据直接存储在这个目录下,而分区表数据存储时,是再划分子目录来存储的。一个分区一个子目录。主要作用是来优化查询性能。
例如:
1 | |
这个日志表以dt字段分区,dt是个虚拟的字段,dt下并不存储数据,而是用来分区的,实际数据存储时,dt字段值相同的数据存入同一个子目录中,插入数据或者导入数据时,同一天的数据dt字段赋值一样,这样就实现了数据按dt日期分区存储。
当Hive查询数据时,如果指定了dt筛选条件,那么只需要到对应的分区下去检索数据即可,大大提高了效率。所以对于分区表查询时,尽量添加上分区字段的筛选条件
创建桶表
桶表也是一种用于优化查询而设计的表类型。创建通表时,指定桶的个数、分桶的依据字段,hive就可以自动将数据分桶存储。查询时只需要遍历一个桶里的数据,或者遍历部分桶,这样就提高了查询效率。
例如:
1 | |
- clustered by是指根据userid的值进行哈希后模除分桶个数,根据得到的结果,确定这行数据分入哪个桶中,这样的分法,可以确保相同userid的数据放入同一个桶中。而经销商的订单数据,大部分是根据user_id进行查询的。这样大部分情况下是只需要查询一个桶中的数据就可以了
- sorted by 是指定桶中的数据以哪个字段进行排序,排序的好处是,在join操作时能获得很高的效率
- into 10 buckets是指定一共分10个桶
- 在HDFS上存储时,一个桶存入一个文件中,这样根据user_id进行查询时,可以快速确定数据存在于哪个桶中,而只遍历一个桶可以提供查询效率
分桶表读写过程如下: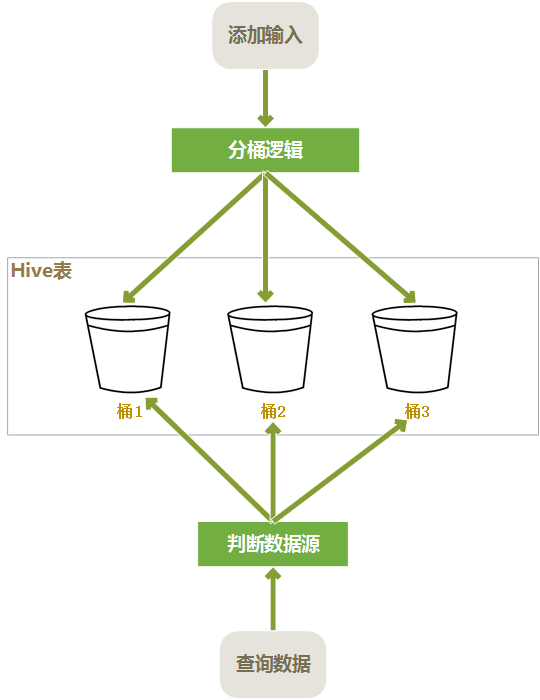
其他表操作
查看表定义:
describe userinfo;查看表的详细信息:
describe formatted userinfo;修改表名:
1
describe formatted userinfo;添加字段:
1
2---在user_info表添加一个字段provinceid,int 类型
alter table user_info add columns (provinceid int );修改字段:
1
alter table user_info replace columns (userid int,username string,cityid int,joindate date,provinceid int);修改字段,只是修改了Hive表的元数据信息(元数据信息一般是存储在MySql中),并不对存在于HDFS中的表数据做修改。并不是所有的Hive表都可以修改字段,只有使用了native SerDe (序列化反序列化类型)的表才能修改字段
删除表:
drop table if exists user_info;
DML操作(数据操作)
加载数据到Hive
加载到普通表
可以将本地文本文件内容批量加载到Hive表中,要求文本文件中的格式和Hive表的定义一致,包括:字段个数、字段顺序、列分隔符都要一致。
例如:
1 | |
- local关键字表示源数据文件在本地,源文件可以在HDFS上,如果在HDFS上,则去掉local,inpath后面的路径是类似”hdfs://namenode:9000/user/datapath”这样的HDFS上文件的路径。
- overwrite关键字表示如果hive表中存在数据,就会覆盖掉原有的数据。如果省略overwrite,则默认是追加数据\
加载到分区表
1 | |
将这批数据加载到dt为2017-05-26的分区中
加载到分桶表
1 | |
set hive.enforce.bucketing = true;表明了启用分桶表
导出数据
将hive数据导出到本地文件(也可导出到HDFS,将local关键字去掉即可)
1 | |
插入数据
insert select导入
这里是将查询结果导入到表中,overwrite关键字是覆盖目标表中的原来数据。如果缺省,就是追加数据:
1 | |
如果插入数据的表是分区表,则需要加入dt
1 | |
hive每次查询都会将结果集遍历一遍,也可以将一个结果集插入多个表,提高效率:
1 | |
复制表
复制表是将源表的结构和数据复制并创建为一个新表,复制过程中,可以对数据进行筛选,列可以进行删减。
对user_leads表进行复制备份,复制时筛选了2016-08-22以前的数据,减少几个列,并添加了一个bakdate列:
1 | |
克隆表
克隆表时会克隆源表的所有元数据信息,但是不会复制源表的数据:
1 | |
备份表
备份是将表的元数据和数据都导出到HDFS上:
1 | |
HQL语句
select查询
指定列
1
2
3
4select * from user_leads;
select leads_id,user_id,create_time from user_leads;
select e.leads_id from user_leads e;函数列, 函数可以是hive自带,也可以是用户自定位的
1
select companyid,upper(host),UUID(32) from user_action_log;算数运算列,可以进行各种算数运算(加减乘除取模等),运算结果做为结果列:
1
select companyid,userid, (companyid + userid) as sumint from useractionlog;限制返回条数, 与mysql limit类似:
1
select * from user_action_log limit 100;Case When Then 条件判断语句:
1
2
3
4---case when 两种写法
select case companyid when 0 then '未登录' else companyid end from user_action_log;
select case when companyid=0 then '未登录' else companyid end from user_action_log;
where筛选
支持:=,<,>,<>(不等于),between and等于mysql类似。
还支持匹配操作,如Link, RLike
group by 分组
Hive不支持having语句,有对group by 后的结果进行筛选的需求,可以先将筛选条件放入group by的结果中,然后在包一层,在外边对条件进行筛选。
如mysql中类似SELECT col1 FROM t1 GROUP BY col1 HAVING SUM(col2) > 10,转换为hive中:
1 | |
子查询
Hive对子查询的支持有限,只允许在 select from 后面出现。比如:
1 | |
并不支持列名中的子查询,如:
1 | |
Join查询
Hive对Join有一些限制,只支持等值连接,并不支持不等连接。原因是Hive语句最终是要转换为MapReduce程序来执行的,但是MapReduce程序很难实现这种不等判断的连接方式。如:
1 | |
并且hive的连接谓词不支持or
1 | |
Inner Join
内连接同Mysql中的一样,连接的两个表中,只有同时满足连接条件的记录才会放入结果表中。
Left join
同MySQL中一样,两个表左连接时,符合Where条件的左侧表的记录都会被保留下来,而符合On条件的右侧的表的记录才会被保留下来。
Right join
同Left Join相反,两个表左连接时,符合Where条件的右侧表的记录都会被保留下来,而符合On条件的左侧的表的记录才会被保留下来。
Full join
Full Join会将连接的两个表中的记录都保留下来。
排序
Order By
order by 的使用与mysql一样,对查询结果进行全局排序,但是Hive语句会放在Hadoop集群中进行MapReduce,如果数据集过大Reduce的过程就会很长,所以尽量不要在Hive中使用order by
Sort By 和 Distribute By
1 | |
Sort By是在每个reduce中进行排序,是一个局部排序,可以保证每个Reduce中是按照userid进行排好序的,但是全局上来说,相同的userid可以被分配到不同的Reduce上,虽然在各个Reduce上是排好序的,但是全局上不一定是排好序的。
1 | |
Distribute By 指定map输出结果怎么样划分后分配到各个Reduce上去,比如Distribute By userid,就可以保证userid字段相同的结果被分配到同一个reduce上去执行。然后再指定Sort By userid,则在Reduce上进行按照userid进行排序。
但是这种还是不能做到全局排序,只能保证排序字段值相同的放在一起,并且在reduce上局部是排好序的。
需要注意的是Distribute By 必须写在Sort By前面。
Cluster By
如果Distribute By和Sort By的字段是同一个,可以简写为 Cluster By.
1 | |
最终结果有序
最终结果是比较大的,一般是取得一个小的结果集,然后在小的结果集上进行order by排序:
1 | |
先用group by获得一个小的结果集,在对晓得结果集进行order by排序
取前N条有序
按某个字段排序后,取出前N条:
1 | |
这个语句是查询username最长的10条记录,实现是先根据username的长度在各个Reduce上进行排序后取各自的前10个,然后再从10*N条的结果集里用order by取前10个。
MapReduce执行过程
Hive语句最终是要转换为MapReduce程序放到Hadoop上去执行的。
MapReduce执行过程简介
MapReduce过程大体分为两个阶段:map函数阶段和reduce函数阶段,两个阶段之间有有个shuffle。
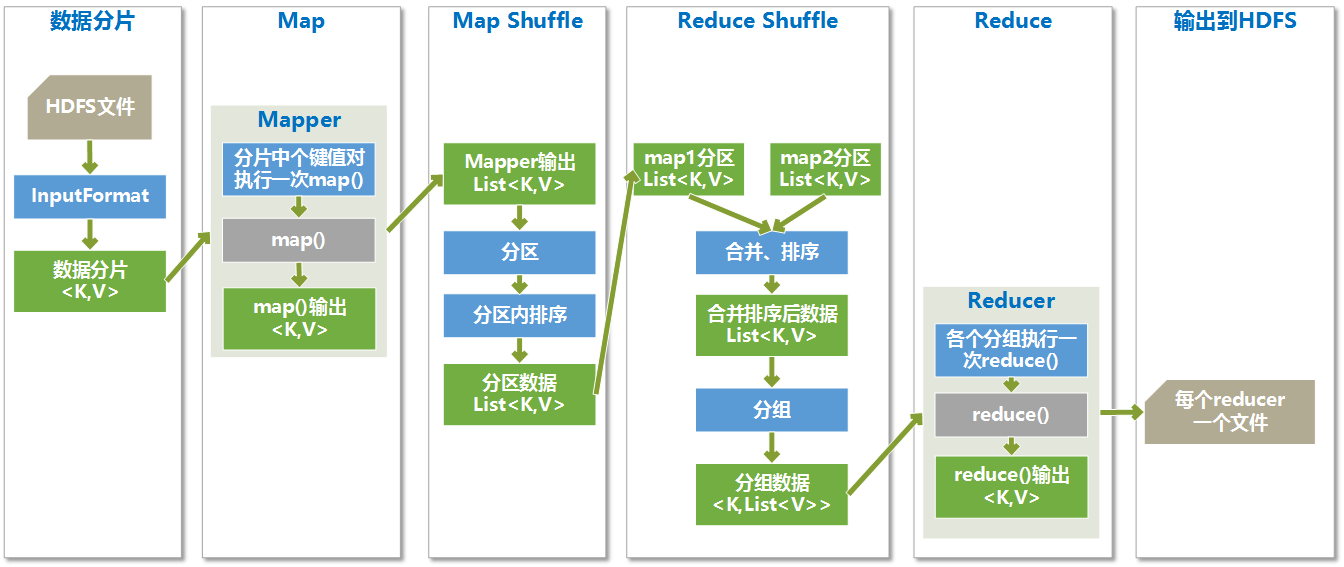
- Hadoop将MapReduce输入的数据划分为等长的小分片,一般每个分片是128M,因为HDFS的每个块是128M
- map函数是数据准备阶段,读取分片内容,并筛选掉不需要的数据,将数据解析为键值对的形式输出,map函数核心目的是形成对数据的索引,以供reduce函数方便对数据进行分析
- 在map函数执行完后,进行map端的shuffle过程,map端的shuffle是将map函数的输出进行分区,不同分区的数据要传入不同的Reduce里去
- 各个分区里的数据传入Reduce后,会先进行Reduce端的Shuffle过程,这里会将各个Map传递过来的相同分区的进行排序,然后进行分组,一个分组的数据执行一次reduce函数
- reduce函数以分组的数据为数据源,对数据进行相应的分析,输出结果为最终的目标数据
- 由于map任务的输出结果传递给reduce任务过程中,是在节点间的传输,是占用带宽的,这样带宽就制约了程序执行过程的最大吞吐量,为了减少map和reduce间的数据传输,在map后面添加了combiner函数来就map结果进行预处理,combiner函数是运行在map所在节点的
执行过程图如: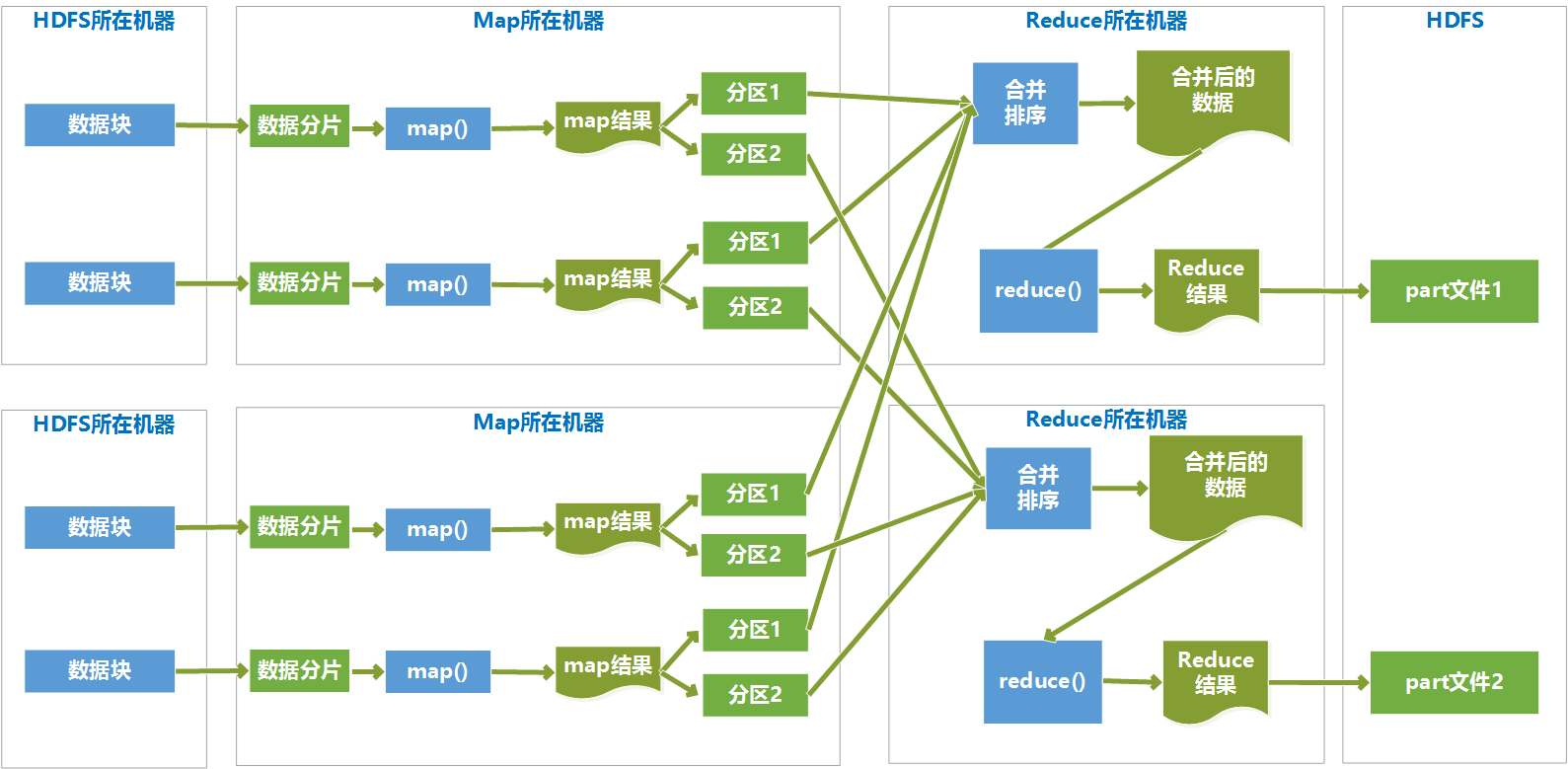
分片
HDFS上的文件要用很多mapper进程处理,而map函数接收的输入是键值对的形式,所以要先将文件进行切分并组织成键值对的形式,这个切分和转换的过程就是数据分片。
Map过程
每个数据分片将启动一个Map进程来处理,分片里的每个键值对运行一次map函数,根据map函数里定义的业务逻辑处理后,得到指定类型的键值对。
Map shuffle过程
Map端的shuffle如下: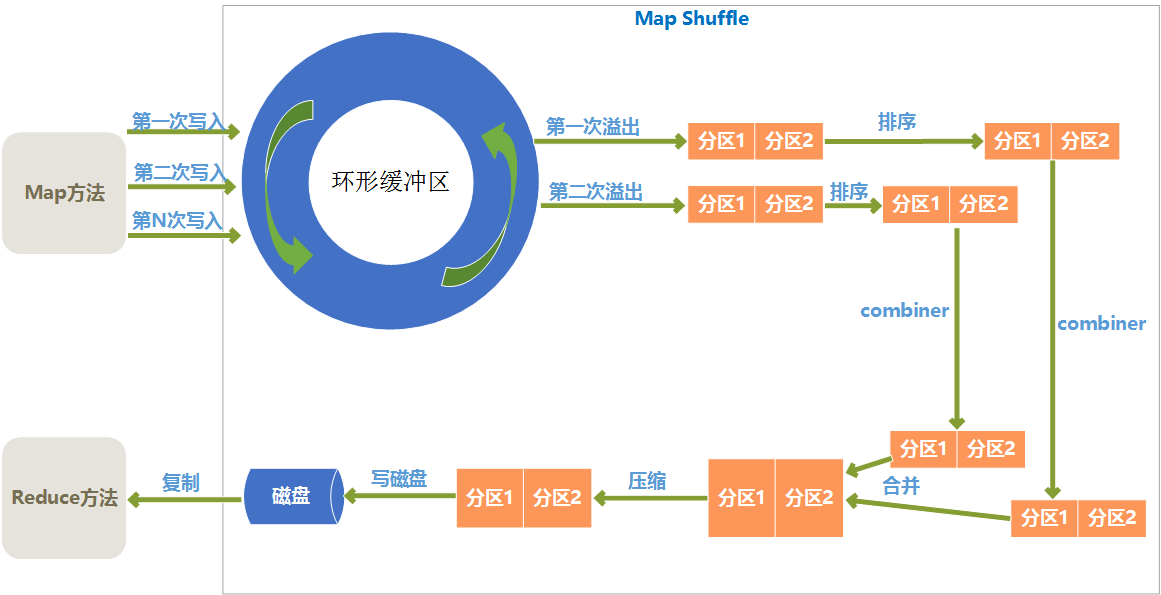
环形缓冲区
Map输出结果是先放入内存中的一个环形缓冲区,这个环形缓冲区默认大小为100M(这个大小可以在io.sort.mb属性中设置),当环形缓冲区里的数据量达到阀值时(这个值可以在io.sort.spill.percent属性中设置)就会溢出写入到磁盘,环形缓冲区是遵循先进先出原则,Map输出一直不停地写入,一个后台进程不时地读取后写入磁盘,如果写入速度快于读取速度导致环形缓冲区里满了时,map输出会被阻塞直到写磁盘过程结束。
分区
从环形缓冲区溢出到磁盘过程,是将数据写入mapred.local.dir属性指定目录下的特定子目录的过程。 但是在真正写入磁盘之前,要进行一系列的操作,首先就是对于每个键,根据规则计算出来将来要输出到哪个reduce,根据reduce不同分不同的区,分区是在内存里分的,分区的个数和将来的reduce个数是一致的
排序
在每个分区上会根据键进行排序
Combiner
combiner方法是对于map输出的结果按照业务逻辑预先进行处理,目的是对数据进行合并,减少map输出的数据量。
排序后,如果指定了conmbiner方法,就运行combiner方法使得map的结果更紧凑,从而减少写入磁盘和将来网络传输的数据量
合并溢出文件
环形缓冲区每次溢出,都会生成一个文件,所以在map任务全部完成之前,会进行合并成为一个溢出文件,每次溢出的各个文件都是按照分区进行排好序的,所以在合并文件过程中,也要进行分区和排序,最终形成一个已经分区和排好序的map输出文件。
在合并文件时,如果文件个数大于某个指定的数量(可以在min.num.spills.for.combine属性设置),就会进再次combiner操作,如果文件太少,效果和效率上,就不值得花时间再去执行combiner来减少数据量了
压缩
Map输出结果在进行了一系列的分区、排序、combiner合并、合并溢出文件后,得到一个map最终的结果后,就应该真正存储这个结果了,在存储之前,可以对最终结果数据进行压缩,一是可以节约磁盘空间,而是可以减少传递给reduce时的网络传输数据量。
默认是不进行压缩的,可以在mapred.compress.map.output属性设置为true就启用了压缩,而压缩的算法有很多,可以在mapred.map.output.compression.codec属性中指定采用的压缩算法
Reduce Shuffle过程
Map端Shuffle完成后,将处理结果存入磁盘,然后通过网络传输到Reduce节点上,Reduce端首先对各个Map传递过来的数据进行Reduce 端的Shuffle操作,Reduce端的Shuffle过程如下所示:
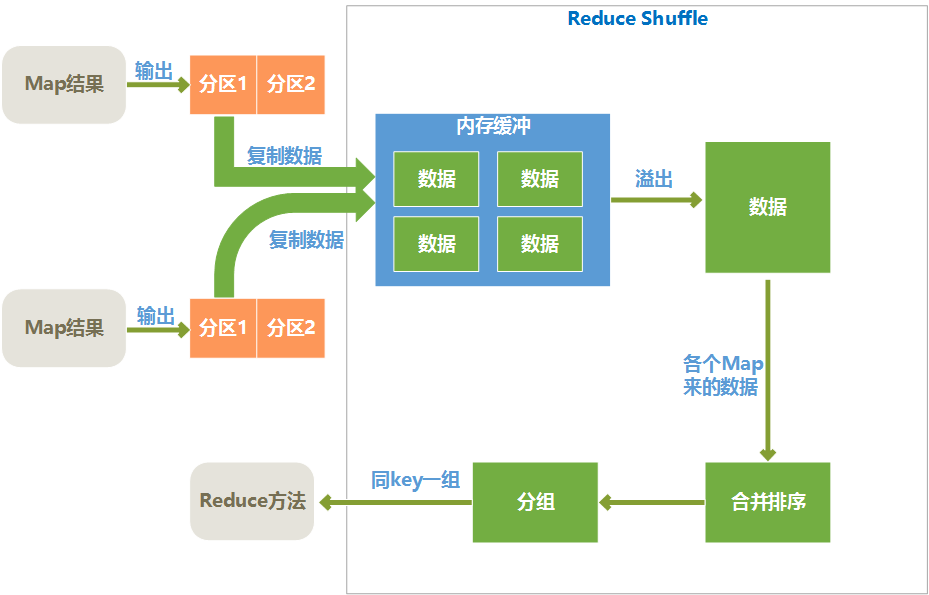
复制数据
各个map完成时间肯定是不同的,只要有一个map执行完成,reduce就开始去从已完成的map节点上复制输出文件中属于它的分区中的数据,reduce端是多线程并行来复制各个map节点的输出文件的,线程数可以在mapred.reduce.parallel.copies属性中设置。
reduce将复制来的数据放入内存缓冲区(缓冲区大小可以在mapred.job.shuffle.input.buffer.percent属性中设置)。当内存缓冲区中数据达到阀值大小或者达到map输出阀值,就会溢写到磁盘。
写入磁盘之前,会对各个map节点来的数据进行合并排序,合并时如果指定了combiner,则会再次执行combiner以尽量减少写入磁盘的数据量。为了合并,如果map输出是压缩过的,要在内存中先解压缩后合并
合并数据
合并排序其实是和复制文件同时并行执行的,最终目的是将来自各个map节点的数据合并并排序后,形成一个文件
分组
分组是将相同key的键值对分为一组,一组是一个列表,列表中每一组在一次reduce方法中处理
执行reduce方法
reduce端的shuffle后,就会执行reduce方法
Reduce端的Shuffle过程后,最终形成了分好组的键值对列表,相同键的数据分为一组,分组的键是分组的键,值是原来值得列表,然后每一个分组执行一次reduce函数,根据reduce函数里的业务逻辑处理后,生成指定格式的键值对。