redis中基本数据结构 redis包含五种数据结构: string,list,hash,set,zset
容器类型通用规则 list/set/hash/zset 这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
create if not exists 如果容器不存在,那就创建一个,再进行操作。
drop if no elements 如果容器里元素没有了,那么立即删除元素,释放内存。
分布式锁 setnx 基本使用 redis提供setnx(set if not exist)指令来使用分布式锁功能:
1 2 3 4 5 6 7 8 9 10 lock :lock -something true do something critical ...lock :lock -something1
为了防止业务逻辑的执行过程中出现异常,导致锁一直得不到释放,就会造成死锁。redis提供了锁的过期时间,到期后锁会自动释放:
1 2 3 4 5 > set lock :lock -something true ex 5 nxdo something critical ...lock :lock -something
超时问题 Redis 的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执行的太长,以至于超出了锁的超时限制,就会出现问题。因为这时候第一个线程持有的锁过期了,临界区的逻辑还没有执行完,这个时候第二个线程就提前重新持有了这把锁,导致临界区代码不能得到严格的串行执行。
所以redis分布式锁尽量不要用于长时间的任务,用来避免超时问题。如果出现了数据小范围的错乱,就需要人工介入来解决来。
可重入性 可重入性是指线程在持有锁的情况下再次请求加锁,如果一个锁支持同一个线程的多次加锁,那么这个锁就是可重入的。类似ReentrantLock,redis要支持可重入锁需要对客户端set方法包装,使线程ThreadLocal变量存储当前锁对计数,Java实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public class RedisWithReentrantLock {private ThreadLocal <Map <String , Integer >> lockers = new ThreadLocal <>();private Jedis jedis;public RedisWithReentrantLock (Jedis jedis) {this .jedis = jedis;private boolean _lock (String keyreturn jedis.set (key, "" , "nx" , "ex" , 5L) != null ;private void _unlock (String keydel (key);private Map <String , Integer > currentLockers (Map <String , Integer > refs = lockers.get ();if (refs != null ) {return refs;set (new HashMap <>());return lockers.get ();public boolean lock (String keyMap <String , Integer > refs = currentLockers ();Integer refCnt = refs.get (key);if (refCnt != null ) {put (key, refCnt + 1 );return true ;boolean ok = this ._lock (key);if (!ok) {return false ;put (key, 1 );return true ;public boolean unlock (String keyMap <String , Integer > refs = currentLockers ();Integer refCnt = refs.get (key);if (refCnt == null ) {return false ;1 ;if (refCnt > 0 ) {put (key, refCnt);else {remove (key);this ._unlock (key);return true ;public static void main (String [] argsJedis jedis = new Jedis ();RedisWithReentrantLock redis = new RedisWithReentrantLock (jedis);System .out .println (redis.lock ("codehole" ));System .out .println (redis.lock ("codehole" ));System .out .println (redis.unlock ("codehole" ));System .out .println (redis.unlock ("codehole" ));
延时队列 Redis 的 list 数据结构常用来作为异步消息队列使用,使用rpush/lpush操作入队,使用lpop 和 rpop 来出队, 这种消息队列没有专业消息中间价的高级特性,比如ack保证,所以不太适用于消息可靠性要求高的场景。
队列的延时 客户端使用pop来获取消息,但是如果队列空了,客户端就会陷入 pop 的死循环,不停地 pop。这样不但拉高了客户端的 CPU,redis 的 QPS 也会被拉高,如果这样空轮询的客户端有几十来个,Redis 的慢查询可能会显著增多。可以用sleep来解决这个问题,让线程停一会儿,这样客户端的cpu和redis的qps都会下降下来。
用睡眠的办法可以解决问题。但是有个小问题,那就是睡眠会导致消息的延迟增大。如果只有 1 个消费者,那么这个延迟就是 1s。如果有多个消费者,这个延迟会有所下降,因为每个消费者的睡觉时间是岔开来的。
更好的解决方法是blpop/brpop,b代表着blocking,也就是阻塞读。阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零。用blpop/brpop替代前面的lpop/rpop,就完美解决了上面的问题
但是使用阻塞读会导致空闲断开的问题,如果线程一直阻塞在哪里,Redis 的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用。这个时候blpop/brpop会抛出异常来。
所以编写客户端消费者的时候要小心,注意捕获异常,还要重试。
延时队列的实现 处理异步消息的时候,需要使用延时队列。
redis中延时队列可以用zset实现,将消息序列化成一个字符串作为 zset 的value,这个消息的到期处理时间作为score,然后用多个线程轮询 zset 获取到期的任务进行处理,多个线程是为了保障可用性,万一挂了一个线程还有其它线程可以继续处理。因为有多个线程,所以需要考虑并发争抢任务,确保任务不能被多次执行。
Redis 的 zrem 方法是多线程多进程争抢任务的关键,它的返回值决定了当前实例有没有抢到任务,因为 loop 方法可能会被多个线程、多个进程调用,同一个任务可能会被多个进程线程抢到,通过 zrem 来决定唯一的属主。java的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 public class RedisDelayingQueue <T> {static class TaskItem <T> {public String id;public T msg;private Type TaskType = new TypeReference <TaskItem <T>>() {getType ();private Jedis jedis;private String queueKey;public RedisDelayingQueue (Jedis jedis, String queueKey) {this .jedis = jedis;this .queueKey = queueKey;public void delay (T msg ) {TaskItem <T> task = new TaskItem <T>();id = UUID .randomUUID ().toString (); msg = msg;String s = JSON .toJSONString (task); zadd (queueKey, System .currentTimeMillis () + 5000 , s); public void loop (while (!Thread .interrupted ()) {Set <String > values = jedis.zrangeByScore (queueKey, 0 , System .currentTimeMillis (), 0 , 1 );if (values.isEmpty ()) {try {Thread .sleep (500 ); catch (InterruptedException e) {break ;continue ;String s = values.iterator ().next ();if (jedis.zrem (queueKey, s) > 0 ) { TaskItem <T> task = JSON .parseObject (s, TaskType ); this .handleMsg (task.msg );public void handleMsg (T msg ) {System .out .println (msg);public static void main (String [] argsJedis jedis = new Jedis ();RedisDelayingQueue <String > queue = new RedisDelayingQueue <>(jedis, "q-demo" );Thread producer = new Thread () {public void run (for (int i = 0 ; i < 10 ; i++) {delay ("codehole" + i);Thread consumer = new Thread () {public void run (loop ();start ();start ();try {join ();Thread .sleep (6000 );interrupt ();join ();catch (InterruptedException e) {
位图(bitmap) 位图(Bitmap)是通过一个 bit 来表示某个元素对应的值或者状态。它并不是什么新的数据结构。它的内容其实就是普通的字符串。我们可以通过 get/set 获取位图的内容,也可以使用getbit/setbit 操作 bit 值(0 或者 1)
bitmap使用 setbit 对某个key的某位赋值。 返回原来存储的位
1 2 redis> setbit bit-key 106 1 integer ) 0
getbit 获取某key某位的值, 返回某位的值,当offset长于key长度或key不存在返回0
1 2 3 4 5 redis> setbit bit-key 106 1 integer ) 0 key 106 integer ) 1
bitop 对多个键进行位操作。 op值得是operation。
用法:bitop operation destkey key1 key2 [key ...]
destkey: 运算结果保存当值 operation: and,or,not,xor(异或) bitcount 计算给定字符串上,位为1的个数。 返回位为1的数量 用法: bitcount key [start] [end]
bittop 获取某个键第一位被设置为 0 或 1 位的位置。
魔术指令,bitfield 。一次对多个位范围进行操作。bitfield 有三个子指令,分别是 get/set/incrby。每个指令都可以对指定片段做操作
用法:bitfield key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
返回值:返回一个数组作为回复, 数组中的每个元素就是对应操作的执行结果
bitmap应用场景示例 统计用户上线次数 每当用户在某一天上线的时候,我们就使用 setbit,以用户名作为 key ,将那天所代表的网站的上线日作为 offset 参数,并将这个 offset 上的位设置为 1
然后通过bitcount可得到用户总共上线次数
统计用户签到次数 原理同上线次数
统计活跃用户 统计某天或者某连续几天,活跃用户数。
方案:若某用户上线,则以日期为KEY,以用户user_id为偏移量(若ID不为整数,则将ID hash化为唯一ID),设置位为 1。 然后bitcount 日期即可得到某天活跃用户数。
某连续两天活跃用户数示例:
1 2 3 4 5 6 7 int status = 1 ;100 ;20180820 ', user_id, status);20180821 ', user_id, status);201808 _20_21', 'active_20180820 ', 'active_20180821 ');201808 _20_21');
HyperLogLog统计大量数据 如果要统计网页当PV,这个需求很好实现,给每个网页增加一个redis计数器,每个请求就incrby一下就好了
如果要统计UV,同一个用户一天之内的多次访问只算做一次,所以要做去重。可以用一个set存储当天访问过某个网页的用户id,当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。
但是当页面的访问量非常大,比如几千万的UV的时候,这个set集合就非常大,会占据很多内存空间。其实我们对UV只是需要一个大概的数字, 100W和101W差别其实不大,redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了
使用方法 HyperLogLog提供了两个指令:pfadd/pfcount,增加计数和获取计数。比如上述统计UV的功能,只需要将用户id,pfadd进去,最后使用pfcount来获取结果就好了。这个结果是带有去重功能的
HyperLogLog还提供了一个pfmerge的指令,用于将多个pfcount的结果合并。
值得注意的是一个HyperLogLog数据结构就占据了12K的空间,所以不太适用于统计范围较小的数据,对于大量数据,HyperLogLog就可以省去很多内存空间
布隆过滤器 布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
它的使用场景可以归纳为:判断大量数据是否在一个池子里
有如下特点:
空间效率和查询效率高 不会漏判,但是有一定的误判率(哈希表是精确匹配) 布隆过滤器原理 想快速找到一个元素,以hash的方式是最快的,常用的有hashmap等结构,但是对于大量数据,使用hashmap显然会占据很多内存。
布隆过滤器优于hashmap的地方就是占用空间很小。实现原理如下:
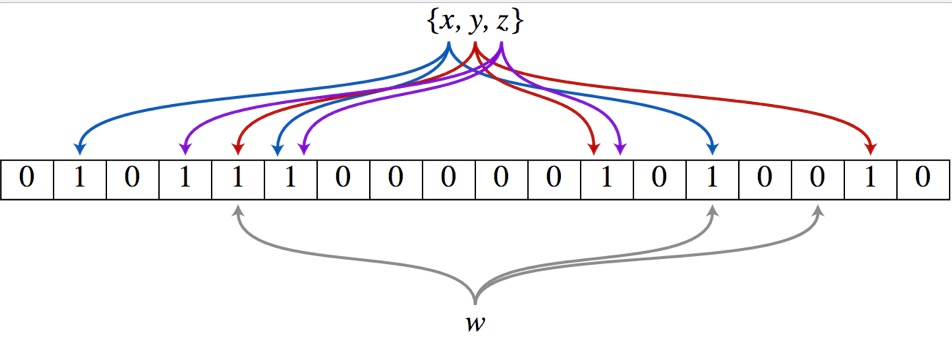
布隆过滤器是一个bit向量,或者说是bit数组 针对一个值,使用多个hash函数,每个hash值指向的地方设置为1 所以当一个数据,通过不同的hash函数映射到的位都有值时,他可能存在。但是任何一位没有值,就代表这个数据必然不存在
redis中布隆过滤器的基本使用 redis可以安装布隆过滤器插件来使用布隆过滤器。
布隆过滤器有两个基本指令:bf.add 添加元素,bf.exists 查询元素是否存在
限流 简单限流 使用 zset 这个数据结构的 score 来充当滑动窗口,保证value唯一即可,Java实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class SimpleRateLimiter {private Jedis jedis;public SimpleRateLimiter (Jedis jedis) {this .jedis = jedis;public boolean isActionAllowed (String userId, String actionKey, int period, int maxCount) {String key = String .format ("hist:%s:%s" , userId, actionKey);long nowTs = System.currentTimeMillis ();pipelined ();multi ();zadd (key , nowTs, "" + nowTs);zremrangeByScore (key , 0 , nowTs - period * 1000 );zcard (key );expire (key , period + 1 );exec ();close ();return count.get () <= maxCount;public static void main (String [] args) {new Jedis ();new SimpleRateLimiter (jedis);for (int i=0 ;i<20 ;i++) {out .println (limiter.isActionAllowed ("laoqian" , "reply" , 60 , 5 ));
漏斗限流 漏斗限流又叫漏桶限流,漏斗以一定速率往下滴水(响应请求), 往漏斗上方灌水(接受请求),如果漏斗满了,就拒绝请求。 以 redis 提供的限流模块: redis-cell实现。
参考资料