kafka参数使用
producer参数
producer发送消息到partition的过程:
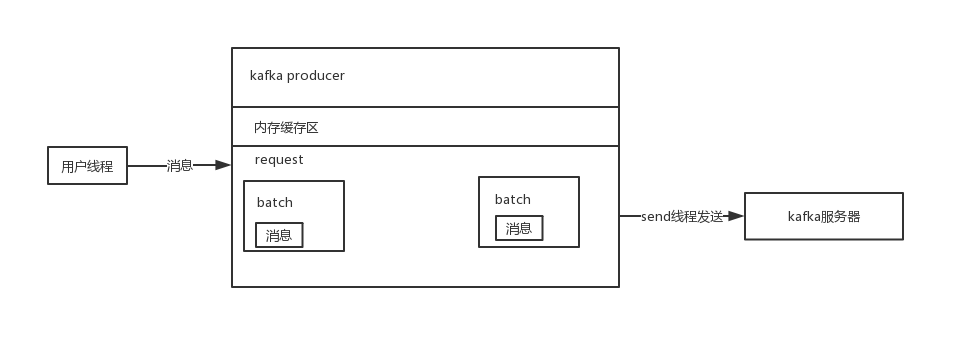
客户端先将消息写入内存缓存, 多个消息形成一个个Batch, 然后send线程将多个Batch打包成一个request发送到kafka服务器上。
acks
acks参数是用来确认消息是否发送成功的。
(1) acks=0
当acks设置为0时,producer只要将消息发送出去,还未写入leader partition当磁盘,即认为消息发送成功。这个情况很容易造成消息丢失
(2) acks=1
这是kafka的默认配置,当acks设置为1的时候,只有 leader partition 接收到消息并成功写入磁盘才算发送成功。但是这种情况并不能保证高可用,如果leader写入了磁盘,follower还未来得及同步leader就宕机了,这样消息也会丢失
(3) acks=all
acks等于all的情况下,只有在 ISR 同步列表里面的
全部follower把消息同步过去,才算发送成功。
buffer.memory
内存缓冲区大小,这个参数到默认大小是 32MB
Kafka的客户端发送数据到服务器,一般都是要经过缓冲的,也就是说,你通过KafkaProducer发送出去的消息都是先进入到客户端本地的内存缓冲里,然后把很多消息收集成一个一个的Batch,再发送到Broker上去的。
如果这个内存设置太小,kafka写入消息很快将内存写满,就会阻塞用户线程无法往里面写入消息。
batch.size
多少个消息可以打成一个batch, 这个参数默认是16KB
加大这个参数可以提高吞吐率,如果将参数改为32KB甚至更大,一个request包就可以放入更多的消息。但是如果设置的过大,发送的消息就会有延迟,没法及时凑满一个batch
linger.ms
当一个batch被创建后,过了linger.ms毫秒后,无论batch有没有凑满,都会将这个batch发送出去。这就避免了一个batch无法凑满,导致消息延迟和堆积。
max.request.size
这个参数决定了每次发送给Kafka服务器请求的最大大小,同时也会限制你一条消息的最大大小也不能超过这个参数设置的值。默认是1MB
如果业务中的消息都是大的报文,就需要适当调整这个参数了
retries和retries.backoff.ms
这两个参数决定了一个请求失败了可以重试几次,每次重试的间隔是多少毫秒。
consumer参数
在consumer参数说明前,先说明consumer的提交消息和offset的保存
consumer 提交(commit)与位移(offset)
consumer调用 poll 时,会返回没有消费当消息。当消息从broker返回消费者时,broker并不跟踪这些消息是否被消费者接收到;Kafka让消费者自身来管理消费的位移,并向消费者提供更新位移的接口,这种更新位移方式称为提交(commit)
rebalance 重平衡
在正常情况下,消费者会发送分区的提交信息到Kafka,Kafka进行记录。当消费者宕机或者新消费者加入时,Kafka会进行重平衡(rebalance),这会导致消费者负责之前并不属于它的分区。重平衡完成后,消费者会重新获取分区的位移。这时就可能产生两种情况:
假如一个消费者在重平衡前后都负责某个分区,如果提交位移比之前实际处理的消息位移要小,那么会导致消息重复消费
假如在重平衡前某个消费者拉取分区消息,在进行消息处理前提交了位移,但还没完成处理宕机了,然后Kafka进行重平衡,新的消费者负责此分区并读取提交位移,此时会“丢失”消息
可以看出,提交offset的方式对消息消费记录有着比较大对影响。
consumer 提交的方式
- 自动提交
这种方式让消费者来管理位移,应用本身不需要显式操作。当我们将enable.auto.commit设置为true,那么消费者会在poll方法调用后每隔5秒(由auto.commit.interval.ms指定)提交一次位移。和很多其他操作一样,自动提交也是由poll()方法来驱动的;在调用poll()时,消费者判断是否到达提交时间,如果是则提交上一次poll返回的最大位移。
需要注意到,这种方式可能会导致消息重复消费。假如,某个消费者poll消息后,应用正在处理消息,在3秒后Kafka进行了重平衡,那么由于没有更新位移导致重平衡后这部分消息重复消费。
- 提交当前位移
设置auto.commit.offset为false,那么应用需要自己通过调用commitSync()来主动提交位移,该方法会提交poll返回的最后位移。
为了避免消息丢失,我们应当在完成业务逻辑后才提交位移。而如果在处理消息时发生了重平衡,那么只有当前poll的消息会重复消费。下面是一个自动提交的代码样例:
1 | |
- 异步提交
手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。当然我们可以减少手动提交的频率,但这个会增加消息重复的概率(和自动提交一样)。另外一个解决办法是,使用异步提交的APIcommitAsync()。以下为使用异步提交的方式,应用发了一个提交请求然后立即返回:
1 | |
fetch.message.max.bytes
这个参数是Consumer每次发起获取消息请求的时候,会发往给broker端指导broker端每次读取partition日志时的最大消息长度。这个值越大有利于减少日志读取的次数,提升broker端获取数据的速度,但越大占的内存也越大。
fetch.min.bytes
这个参数允许消费者指定从broker读取消息时最小的数据量。当消费者从broker读取消息时,如果数据量小于这个阈值,broker会等待直到有足够的数据,然后才返回给消费者。对于写入量不高的主题来说,这个参数可以减少broker和消费者的压力,因为减少了往返的时间。而对于有大量消费者的主题来说,则可以明显减轻broker压力
enable.auto.commit
这个参数指定了消费者是否自动提交消费位移,默认为true。如果需要减少重复消费或者数据丢失,你可以设置为false
最佳实践
消息不丢失保证
不要使用producer.send(msg),而要使用producer.send(msg, callback)。记住,一定要使用带有回调通知的send方法。
设置acks = all。acks是Producer的一个参数,代表了你对“已提交”消息的定义。如果设置成all,则表明所有副本Broker都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义。
设置retries为一个较大的值。这里的retries同样是Producer的参数,对应前面提到的Producer自动重试。当出现网络的瞬时抖动时,消息发送可能会失败,此时配置了retries > 0的Producer能够自动重试消息发送,避免消息丢失。
设置unclean.leader.election.enable = false。这是Broker端的参数,它控制的是哪些Broker有资格竞选分区的Leader。如果一个Broker落后原先的Leader太多,那么它一旦成为新的Leader,必然会造成消息的丢失。故一般都要将该参数设置成false,即不允许这种情况的发生。
设置replication.factor >= 3。这也是Broker端的参数。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
设置min.insync.replicas > 1。这依然是Broker端参数,控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于1可以提升消息持久性。在实际环境中千万不要使用默认值1。
确保replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成replication.factor = min.insync.replicas + 1。
确保消息消费完成再提交。Consumer端有个参数enable.auto.commit,最好把它设置成false,并采用手动提交位移的方式。就像前面说的,这对于单Consumer多线程处理的场景而言是至关重要的。
参考资料
- [kafka权威指南]
- kafka参数调优实战
- kafka消费者:从kafka中读取数据