网络IO编程(阻塞/非阻塞/同步/异步)
网络包接收流程
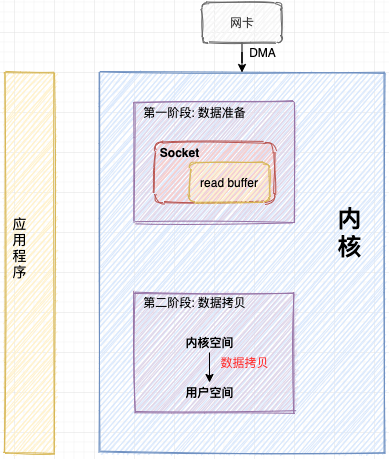
可以将网络数据包接收抽象总结为两个阶段:
- 数据准备阶段: 在这个阶段,网络数据包到达网卡,通过
DMA的方式将数据包拷贝到内存中,然后经过硬中断,软中断,接着通过内核线程ksoftirqd经过内核协议栈的处理,最终将数据发送到内核Socket的接收缓冲区中。 - 数据拷贝阶段: 当数据到达内核Socket的接收缓冲区中时,此时数据存在于
内核空间中,需要将数据拷贝到用户空间中,才能够被应用程序读取。
阻塞与非阻塞
阻塞与非阻塞的区别主要发生在第一阶段:数据准备阶段:
在数据准备阶段,当Socket的接收缓冲区中没有数据的时候,
阻塞模式下应用线程会一直等待。非阻塞模式下应用线程不会等待,系统调用直接返回错误标志EWOULDBLOCK。当Socket的接收缓冲区中有数据的时候,阻塞和非阻塞的表现是一样的,都会进入第二阶段等待数据从内核空间拷贝到用户空间,然后系统调用返回。
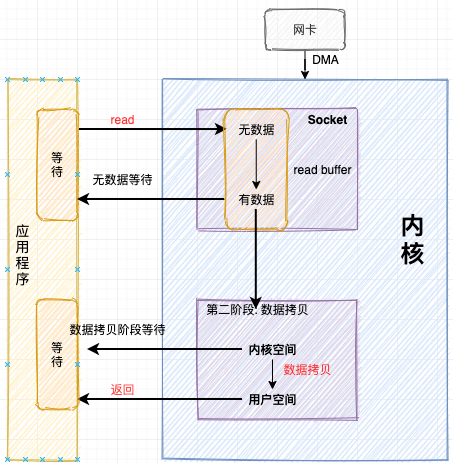
阻塞模式IO(Blocking IO)
当应用程序发起系统调用read时,线程从用户态转为内核态,读取内核Socket接收缓冲区中的数据。
如果这时内核Socket的接收缓冲区没有数据,那么线程就会一直等待,直到Socket接收缓冲区有数据为止。随后将数据从内核空间拷贝到用户空间,系统调用read返回
JAVA BIO编程模型
Java中的实现即是最原始的SocketChannel然后accept
传统BIO编程模型实现如下:
1 | |
socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里;但CPU是被释放出来的,开启多线程,就可以让CPU去处理更多的事情。
这也是所有使用多线程的本质:
- 利用多核
- 当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源
BIO模型最本质的问题在于,严重依赖于线程,但线程资源是宝贵的,主要表现于:
- 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程(Linux中线程并没有定义特殊的数据结构)。创建和销毁都是重量级的系统函数
- 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPU sy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大
当连接数过大的时候,BIO模型是无法应对的
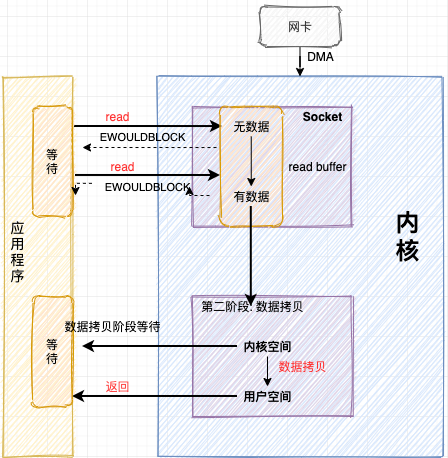
非阻塞IO(Nonblocking IO)
从下图可以看出非阻塞的在数据准备阶段不会等待,系统调用返回EWOULDBLOCK, 但是在第二阶段还是会等待。
JAVA NIO 编程模型
JAVA 中非阻塞 IO 的核心在于使用一个 Selector 来管理多个通道,可以是 SocketChannel,也可以是 ServerSocketChannel,将各个通道注册到 Selector 上,指定监听的事件。
之后可以只用一个线程来轮询这个 Selector,看看上面是否有通道是准备好的,当通道准备好可读或可写,然后才去开始真正的读写(查看每个通道Socket接收缓冲区有中无数据,无数据系统调用立马返回,并带有一个 EWOULDBLOCK 错误,这个阶段用户线程不会阻塞,也不会让出CPU,而是会继续轮训直到Socket接收缓冲区中有数据为止。)
Java中我们将SocketChannel注册到Selector上,即是这种模式, NIO 中 Selector 是对底层操作系统实现的一个抽象,管理通道状态其实都是底层系统实现的,这里简单介绍下在不同系统下的实现:
- select:最早的NIO模型,但是只支持注册1024个socket
- poll:poll 是 select 的代替者, poll 不在限制socket的数量, 但是他与 select 一样, 它们都只会告诉你有几个通道准备好了,但是不会告诉你具体是哪几个通道, 需要自己进行一次扫描,这样当通道数量很大的时候,扫描一次的时间都很长。
- epoll:epoll 能直接返回准备好的通道。
在JDK NIO 中,我们只需要面向 Selector 编程即可:
1 | |
与阻塞IO相比, 非阻塞IO减少了一部分系统资源开销, 但是它仍然有很大的性能问题,因为在非阻塞IO模型下,需要用户线程去不断地发起系统调用去轮训Socket接收缓冲区,这就需要用户线程不断地从用户态切换到内核态,内核态切换到用户态。随着并发量的增大,这个上下文切换的开销也是巨大的。
多路复用就是为了优化这个问题, 操作系统提供了一些系统调用(select、poll、epoll)解决了在非阻塞IO中需要不断的发起系统IO调用去轮询各个连接上的Socket接收缓冲区所带来的用户空间与内核空间不断切换的系统开销。系统调用将轮询的操作交给了内核来帮助我们完成,从而避免了在用户空间不断的发起轮询所带来的的系统性能开销。
同步与异步
同步与异步主要的区别发生在第二阶段:数据拷贝阶段。
前边提到在数据拷贝阶段主要是将数据从内核空间拷贝到用户空间。然后应用程序才可以读取数据。
当内核Socket的接收缓冲区有数据到达时,进入第二阶段。
同步模式在数据准备好后,是由用户线程的内核态来执行第二阶段。所以应用程序会在第二阶段发生阻塞,直到数据从内核空间拷贝到用户空间,系统调用才会返回。异步模式下是由内核来执行第二阶段的数据拷贝操作,当内核执行完第二阶段,会通知用户线程IO操作已经完成,并将数据回调给用户线程。所以在异步模式下 数据准备阶段和数据拷贝阶段均是由内核来完成,不会对应用程序造成任何阻塞。