并发计数器 并发环境重计数 AtomicLong 的 Add 操作是依赖自旋不断的 CAS 去累加一个 Long 值。如果在竞争激烈的情况下,CAS 操作不断的失败,就会有大量的线程不断的自旋尝试 CAS 会造成 CPU 的极大的消耗。
LongAdder 功能类似于 AtomicLong, 在低并发情况下两者表现差不多, 高并发下 LongAdder 的表现就好很多。LongAdder 实现于 Striped64
Striped64 Striped64 对外的语义是一个数字,在内部将数字的“值”拆成了好几部分:一个base变量和一个cells数组。
成员变量 1 2 3 4 5 6 7 8 9 10 11 12 13 abstract class Striped64 extends Number {static final int NCPU = Runtime .getRuntime().availableProcessors();transient volatile Cell[] cells;transient volatile long base;transient volatile int cellsBusy;
Cell 类是通过 CAS 更新的, 有点类似 AtomicLong(volatile 变量、Unsafe 加上字段的偏移量,再用 CAS 提供修改能力), 定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @sun .misc.Contended static final class Cell volatile long value;long x) { value = x; }final boolean cas (long cmp, long val) return UNSAFE.compareAndSwapLong (this , valueOffset, cmp, val) private static final sun.misc.Unsafe UNSAFE;private static final long valueOffset;static {try {"value" ));catch (Exception e) {throw new Error(e);
Cell 类中只有一个用来保存计数的变量 Value , 并提供了CAS操作, Striped64 在 Cell 的基础上提供了 longAccumulate 和 doubleAccumulate 两个计数方法
longAccumulate 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {int h;if ((h = getProbe()) == 0 ) {true ;boolean collide = false ; for (;;) {as ; Cell a; int n; long v;if ((as = cells) != null && (n = as .length) > 0 ) { if ((a = as [(n - 1 ) & h]) == null ) { if (cellsBusy == 0 ) { new Cell(x);if (cellsBusy == 0 && casCellsBusy()) {boolean created = false ;try { int m, j;if ((rs = cells) != null &&0 &&1 ) & h] == null ) {true ;finally {0 ;if (created) break ;continue ; false ;else if (!wasUncontended) true ; else if (a.cas(v = a.value, ((fn == null ) ? v + x : break ;else if (n >= NCPU || cells != as ) false ; else if (!collide) true ;else if (cellsBusy == 0 && casCellsBusy()) {try {if (cells == as ) { new Cell[n << 1 ];for (int i = 0 ; i < n; ++i)as [i];finally {0 ;false ;continue ; else if (cellsBusy == 0 && cells == as && casCellsBusy()) { boolean init = false ;try { if (cells == as ) {new Cell[2 ];1 ] = new Cell(x);true ;finally {0 ;if (init)break ;else if (casBase(v = base, ((fn == null ) ? v + x :break ;
在 longAccumulate 中有几个标记位:
cellsBusy cells 的操作标记位,如果正在修改、新建、操作 cells 数组中的元素会,会将其 cas 为 1,否则为0。wasUncontended 表示 cas 是否失败,如果失败则考虑操作升级。collide 是否冲突,如果冲突,则考虑扩容 cells 的长度。整个 for(;;) 死循环,都是以 cas 操作成功而告终。否则则会修改上述描述的几个标记位,重新进入循环。包含几种情况:
cells 不为空
如果 cell[i] 某个下标为空,则 new 一个 cell,并初始化值,然后退出 如果 cas 失败,继续循环 如果 cell 不为空,且 cell cas 成功,退出 如果 cell 的数量,大于等于 cpu 数量或者已经扩容了,继续重试。(扩容没意义) 设置 collide 为 true。 获取 cellsBusy 成功就对 cell 进行扩容,获取 cellBusy 失败则重新 hash 再重试。 cells 为空且获取到 cellsBusy ,init cells 数组,然后赋值退出。
cellsBusy 获取失败,则进行 baseCas ,操作成功退出,不成功则重试。
doubleAccumulate doubleAccumulate 的整体逻辑与 longAccumulate 几乎一样,区别在于将 double 存储成 long 时需要转换。例如在创建 cell 时:
1 Cell r = new Cell(Double.doubleToRawLongBits(x))
doubleToRawLongBits 是一个 native 方法,将 double 转成 long。在累加时需要再转来回:
1 2 3 4 5 6 7 else if (a .cas(v = a.value,fn == null) ?Double .longBitsToDouble(v ) + x) : // 转回 double 做累加fn .applyAsDoubleDouble .longBitsToDouble(v ), x)))))
伪共享 上面可以看到 Cell 类被 @sun.misc.Contended 注解了, 是用来避免缓存的伪共享, 减少CPU缓存级别竞争, 这里在并发队列 Disruptor 也有用上。
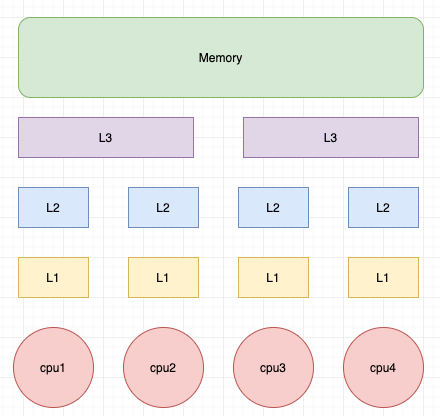
CPU Cache Line 在计算机的架构中 L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。
Cache 是由很多个cache line(缓存行)组成的。每个cache line通常是 64 字节,并且它有效地引用主内存中的一块地址。一个Java的long类型变量是 8 字节,因此在一个缓存行中可以存 8 个long类型的变量。
利用 cache line 特性与不使用比较, 性能相差一倍以上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static long [][] arr;public static void main(String[] args) {new long [1024 * 1024 ][];for (int i = 0 ; i < 1024 * 1024 ; i++) {new long [8 ];for (int j = 0 ; j < 8 ; j++) {0 L;long sum = 0 L;long marked = System.currentTimeMillis();for (int i = 0 ; i < 1024 * 1024 ; i+=1 ) {for (int j =0 ; j< 8 ;j++){sum += arr[i][j];"Loop times:" + (System.currentTimeMillis() - marked) + "ms" );for (int i = 0 ; i < 8 ; i+=1 ) {for (int j =0 ; j< 1024 * 1024 ;j++){sum = arr[j][i];"Loop times:" + (System.currentTimeMillis() - marked) + "ms" );################ 20 ms42 ms
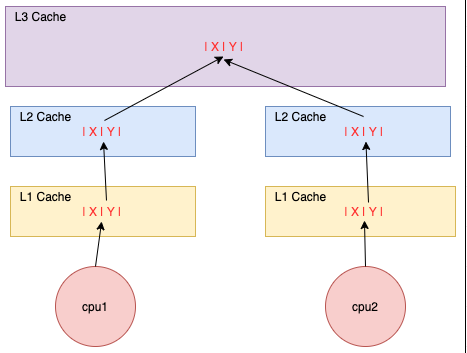
伪共享 多个线程并发的修改一个缓存行中的不同变量的时候, 比如CPU1更新X, CPU2更新Y, 但是X和Y在同一个缓存行上,每个线程都要去竞争缓存行的所有权来更新变量。
避免伪共享 避免伪共享的情况出现, 就需要让可能出现线程竞争的变量分开到不同的 Cache Line 中, 使用空间换时间的思维。
1 2 3 4 5 6 7 8 public final static class ValuePadding { protected long p1, p2, p3, p4, p5, p6, p7; protected volatile long value = 0L; protected long p9, p10, p11, p12, p13, p14, p15;
JDK8 有专门的注解 @Contended 来避免伪共享, Striped64 也是被 @Contended 所修饰
LongAdder LongAdder 继承于 Striped64, 也就继承了成员变量 cells 数组, base 变量和 Accumulate 逻辑。 add 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void add (long xas ; long b, v; int m; Cell a;if ((as = cells) != null || !casBase(b = base , b + x)) {true ;if (as == null || (m = as .length - 1 ) < 0 ||as [getProbe() & m]) == null ||value , v + x)))null , uncontended);