MySQL与缓存一致性问题
引入缓存带来的问题
引入缓冲实际上是一个空间换时间的问题, 意味着数据同时存在于多个空间(最常见就是 Redis 和 MYSQL)。
实际上,最权威最全的数据还是在 MySQL 里的。而万一 Redis数据没有得到及时的更新(例如数据库更新了没更新到Redis),就出现了数据不一致。
大部分情况下,只要使用了缓存,就必然会有不一致的情况出现,只是说这个不一致的时间窗口是否能做到足够的小。有些不合理的设计可能会导致数据持续不一致,这是我们需要改善设计去避免的。
缓存不一致情况分析
更新缓存的方式
在处理查询请求的时候, 逻辑一般如下:
1 | |
流程如图: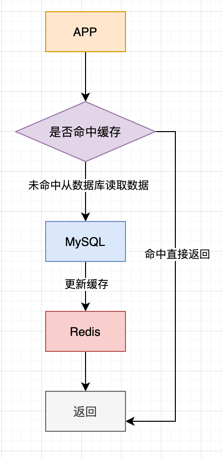
查询缓存的逻辑: 优先查询缓存,查询不到才查询数据库。如果这时候数据库查到数据了,就将缓存的数据进行更新。 这个策略叫 cache aside, 也是最常用的策略。
引发数据不一致的来源主要是处理写请求的时候, 当处理写请求的时候, 会产生两个问题:
- 更新缓存还是删除缓存
- (如果是删除缓存)先更新数据库还是先删除缓存
更新缓存还是删除缓存
先说结论, 选择删除缓存。
如果选择更新缓存, 又分为两个情况:
- 先更新数据库, 再更新缓存
- 先更新缓存, 再更新数据库
针对第一种情况, 先更新数据库:
| 时序 | 线程A | 线程B | 问题 |
|---|---|---|---|
| T1 | 更新数据库为5 | ||
| T2 | 更新数据库为 6 | ||
| T3 | 更新缓存为 6 | ||
| T4 | 更新缓存为5 | 此刻缓存数据为5, 数据库的值是6, 发生了缓存覆盖 |
在看看先更新缓存的情况:
| 时序 | 线程A | 线程B | 问题 |
|---|---|---|---|
| T1 | 更新缓存为 5 | ||
| T2 | 更新缓存为 6 | ||
| T3 | 更新数据库为 6 | ||
| T4 | 更新数据库为5 | 此时缓存为5, 数据库为6, 还是发生了缓存覆盖 |
另外从事务的角度来看, 先更新缓存再更新数据库的代码:
1 | |
可以看出, 如果第一步成功, 第二步失败, 就算没有并发的情况下, 数据库发生了回滚, 而缓存已经更新了, 这里缓存就存的是脏数据了, 是业务无法接受的。
删除缓存
先删除缓存再更新数据库
首先看先删除缓存的情况
两个线程同时做更新操作, 由于网络问题可能发生如下时序:
| 时序 | 线程A | 线程B | 问题 |
|---|---|---|---|
| T1 | 删除数据X的缓存 | ||
| T2 | 读取X,缓存MISS, 从数据库读取 6 | ||
| T3 | 更新数据库中X的值为 5 | ||
| T4 | 将数据库读取的6写回缓存 | 此刻数据库中X是5,而缓存中的值是6 |
这里可以看到读请求可能回把一个旧值给写回了缓存, 导致不一致, 但是这里可以使用延迟双删的策略来处理:
| 时序 | 线程A | 线程C | 线程D | 问题 |
|---|---|---|---|---|
| T5 | Sleep(N) | 读取到缓存旧值 | 此刻所有线程读取到的都是脏数据 | |
| T6 | 删除缓存数据 | |||
| T7 | 更新数据库中X的值 | 缓存miss, load数据库值到缓存 |
我们在更新完数据库后, 做了一个操作 Sleep(N), 然后再做了一次删除, 把缓存中的脏数据删除了。
这个方法的难点在于对 N 的时间的判断,如果 N 时间太短,线程 A 第二次删除缓存的时间依旧早于线程 B 把脏数据写回缓存的时间,那么相当于做了无用功。而 N 如果设置得太长,那么在触发双删之前,新请求看到的都是脏数据。
先更新数据库再删除缓存
| 时序 | 线程A | 线程B | 问题 |
|---|---|---|---|
| T1 | 查询缓存 X Miss, 从数据库读取5 | ||
| T2 | 更新数据库 X=6 | ||
| T3 | 删除缓存 | ||
| T4 | 将5写回缓存 X | 此刻数据库中X是6,而缓存中的值是5 |
虽然这种场景出现的概率比较严格(很少出现并发量大的时候缓存 miss 的情况), 但是也会造成不一致的情况。
这种情况我们一般为业务设置了一个过期时间, 这种极少量的脏数据会在缓存过期后再次 load 到正确的值。
缓存操作的其他问题
删除缓存失败
在 先更新数据库,再删除缓存的场景中, 如果更新数据库的操作成功, 但是由于网络或其他原因删除缓存失败了(不讨论回滚数据库事务的情况, 本身事务的粒度要越小越好, 而且因为缓存操作失败而回滚已经更新好的数据库得不偿失), 也会造成一段时间的数据库不一致。
数据库主从同步产生延时
在查询请求的操作中, 回源缓存是从数据库中 select 数据, 读请求一般是读的从库, 如果发生主从延迟, 这里可能主库已经更新了, 但是从库还是原来的数据, 也会造成脏数据。
如果考虑兼容这种情况, 还是可以使用延迟双删, sleep 的时间在加上主从延迟的时间即可
综合性较强的方案:解析 binlog 来操作缓存
有一种业界比较常用, 但是设计和编码成本是最高的方案, 如果对一致性的要求非常高 ,可以使用这种方案:
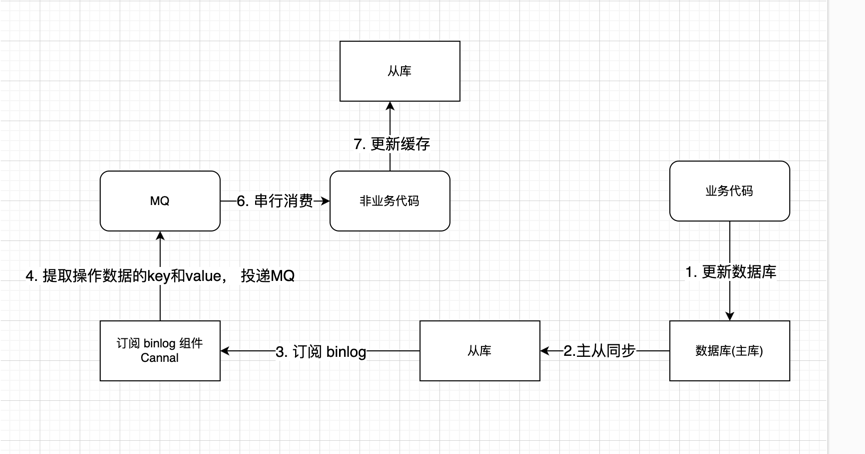
这里有几个注意点:
- 从从库拉 binlog 而不是主库。 防止主从同步延迟 ,主库更新了,MQ 将主库的值更新了缓存, 但是查询请求的时候将从库的值覆盖了缓存造成不一致。
- 引入 MQ 串行消费 binlog 解析后的数据, 防止更新缓存并行覆盖。另一点, 也防止操作缓存失败, MQ 可以重复消费, 成功再提交 offset