disruptor 介绍 Disruptor 是LMAX公司开源的一个高效的内存无锁队列,一个高性能的异步处理框架,或者可以认为是最快的消息框架(轻量的JMS),也可以认为是一个观察者模式实现,或者事件-监听模式的实现,直接称disruptor模式。disruptor最大特点是高性能,其LMAX架构可以获得每秒6百万订单,用1微秒的延迟获得吞吐量为100K+。
disruptor 设计 disruptor 的关键优化设计:
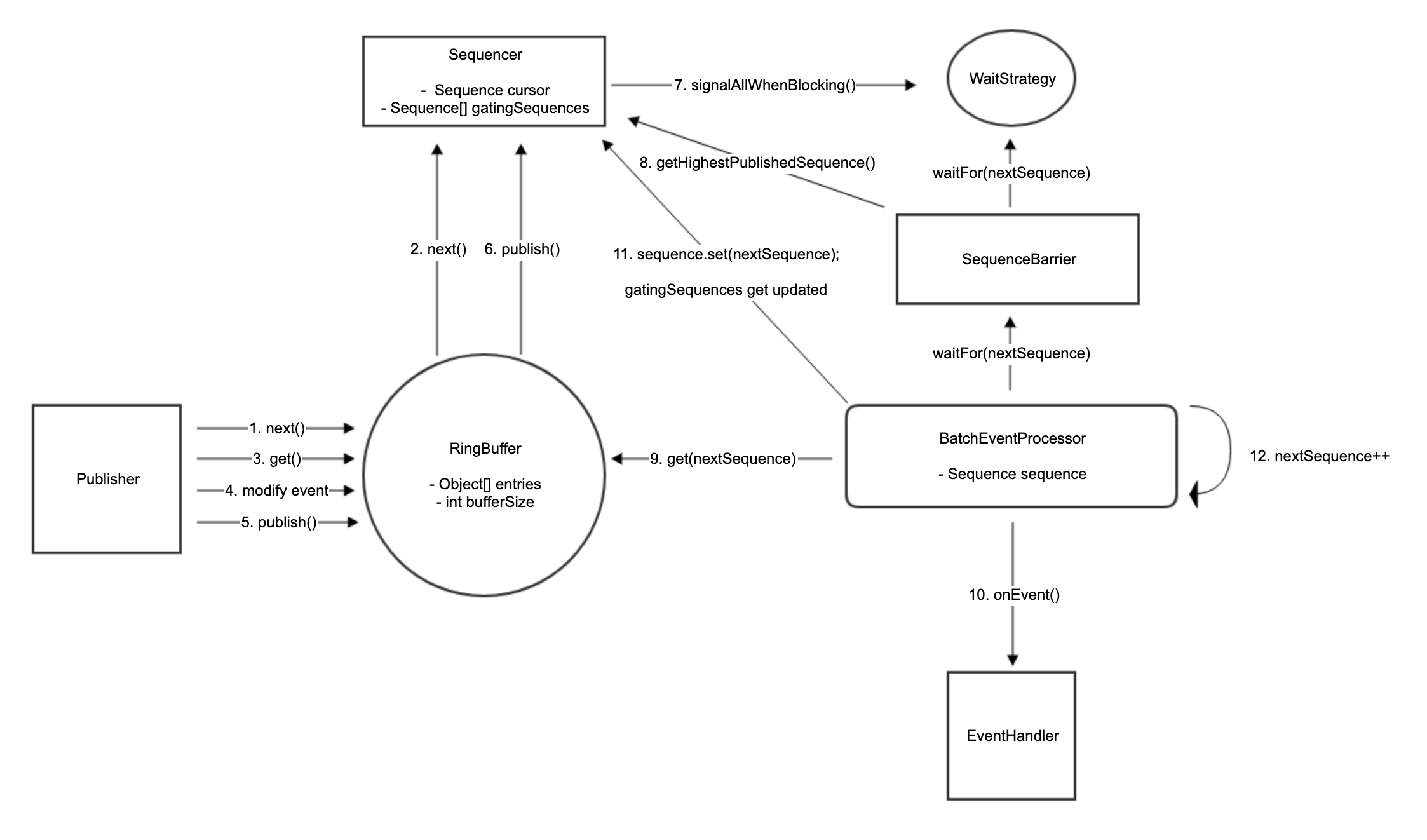
使用环形队列(Ring Buffer)作为底层存储 环形队列中对象都是预先建立好的, 减少了频繁创建/回收对象带来的开销 生产者使用两阶段提交的方式来发布事件(第一阶段是先在环形队列中预占一个空位,第二阶段是向这个空位中写入数据,竞争只发生在第一阶段), 并使用CAS无锁化操作来解决冲突 使用缓存填充来解决伪共享的问题 核心组件 RingBuffer: 环形缓冲区,本质是一个定长Object数组(后续称里面的格子为slot),为了避免伪共享,在这个数组的两端额外填充了若干空位
Sequence: 类似于AtomicLong,用于标记事件id。所有生产者共用一个Sequence,用于不冲突的将事件放到RingBuffer上。每个消费者自己维护一个Sequence,用于标记自己当前正在处理的事件的id
Sequencer: 生产者访问RingBuffer时的控制器,主要实现有两种:SingleProducerSequencer 与 MultiProducerSequencer 分别用于单生产者和多生产者的场景
SequenceBarrier: 只有一个实现类为ProcessingSequenceBarrier 用于协调生产者与消费者(如果某个slot中的事件还没有被所有消费者消费完毕,那么这个slot是不能被复用的,需要等待)
WaitStrategy: 消费者等待下一个可用事件的策略,Disruptor自带了多种WaitStrategy的实现,可以根据场景自行选择。
使用示例 disruptor 简单使用如下:
1 2 3 4 5 6 7 8 9 Disruptor<Element> disruptor = new Disruptor<>(Element::new , 1024 ,(EventHandler<Element>) (event, sequence, endOfBatch) ->((event, sequence) -> event.set(1 )) ;// sleep 一下 让消费者可以执行到 因为消费线程是守护线程 Thread .sleep (1000 ) ;
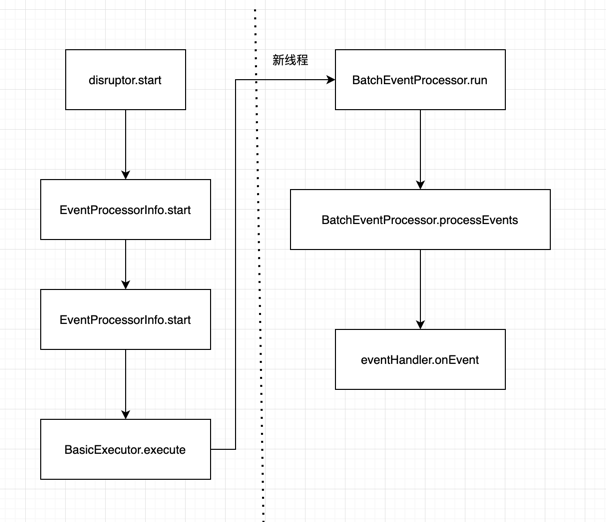
工作流程
源码分析 disruptor 构造函数 disruptor 一个参数完整的构造函数如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public Disruptor ( final EventFactory<T> eventFactory, final int ringBufferSize, final ThreadFactory threadFactory, final ProducerType producerType, final WaitStrategy waitStrategy) this (new BasicExecutor(threadFactory));private Disruptor (final RingBuffer<T> ringBuffer, final Executor executor) this .ringBuffer = ringBuffer;this .executor = executor;
eventFactory: 事件构造器 ringBufferSize: RingBuffer的长度 threadFactory: 消费线程的创建工厂 producerType: 单生产者模式还是多生产者模式(默认是MULTI) waitStrategy: 当RingBuffer中没有可消费的Event时消费者的等待策略(默认是BlockingWaitStrategy) 上面通过5个参数构造出了一个RingBuffer和一个Executor,而这两个组件构成了一个Disruptor。
RingBuffer RingBuffer 的创建:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 public static <E> RingBuffer<E> create(switch (producerType)case SINGLE:return createSingleProducer(factory, bufferSize, waitStrategy);case MULTI:return createMultiProducer(factory, bufferSize, waitStrategy);default :throw new IllegalStateException (producerType.toString());public static <E> RingBuffer<E> createSingleProducer(new SingleProducerSequencer (bufferSize, waitStrategy);return new RingBuffer <E>(factory, sequencer);super (eventFactory, sequencer);this .sequencer = sequencer;this .bufferSize = sequencer.getBufferSize();if (bufferSize < 1 )throw new IllegalArgumentException ("bufferSize must not be less than 1" );if (Integer.bitCount(bufferSize) != 1 )throw new IllegalArgumentException ("bufferSize must be a power of 2" );this .indexMask = bufferSize - 1 ;this .entries = new Object [sequencer.getBufferSize() + 2 * BUFFER_PAD];private void fill(EventFactory<E> eventFactory)for (int i = 0 ; i < bufferSize; i++)new Instance ();
整体的逻辑还是比较清晰, 需要注意的是两点:
RingBuffer 的实际 size 是: bufferSize + 2*BUFFER_PAD, 用来解决伪共享 ring 的原因在于 sequence 是不断增加的 long 类型, 而实际访问下标需要通过 sequence & mask 计算出来 EventFactor EventFactory 是一次性使用的类,在最开始的时候用来给RingBuffer预填充数据。
为了避免JAVA GC带来的性能影响,Disruptor采用的设计是在数组上预填充好对象,每次publish event的时候,只是通过RingBuffer.get(seq)拿到对象,更新对象的值,然后就发布出去了。整个生产消费过程中再也不会有event对象的创建和销毁。
Sequence sequence 是用来表达event序例号的对象。为了高并发下的可见性,肯定不能直接用long的,至少也是volatile long。但Disruptor觉得volatile long还是不够用,所以创造了Sequence类。volatile long, 除此之外还支持:
CAS更新 order writes (Store/Store barrier,改动不保证立即可见) vs volatile writes (Store/Load barrier,改动保证立即可见) 在 volatile 字段 附近添加 padding 解决伪共享问题 在整个框架中可以看到在不同的类里,不同场景下对sequence的表达,有时用long,有时用的Sequence类,这其实是背后对于效率和高并发可见性的考量。
比如在对EventProcessor.sequence的更新中都是用的order writes,不保证立即可见,但速度快很多。在这个场景里,造成的结果是显示的消费进度可能比实际上慢,导致生产者有可能在可以生产的情况下没有去生产。但生产者看的是多个消费者中最慢的那个消费进度,所以影响可能没有那么大。
生产者 生产者 Sequencer 是 Disruptor 框架的核心类。
生产者发布 event 的时候首先需要预定一个 sequence,Sequencer 就是计算和发布 sequence 的。它主要有2个实现类: SingleProducerSequencer 和 MultiProducerSequencer
生产者 publishEvent 步骤:
通过Sequencer.next(n) 来预定下面n个可以写入的数据位,然后修改数据 Sequencer.publish 发布event SingleProducerSequencer 但因为RingBuffer是环形的,一个 size 16 的RingBuffer当你拿到 sequence 为16时相当于又要去写 RingBuffer[0] 的位置了,假如之前的数据还没被消费过就会被覆盖了。Sequencer是这样解决这个问题的,它在内部维护了一个:
1 volatile Sequence [] gatingSequences = new Sequence [0 ];
每个消费者会维护一个自己的 Sequence 对象,来记录自己已经消费到的序例位置。 每添加一个消费者,都会把消费者的Sequence引用添加到 gatingSequences 中。 通过访问 gatingSequences,Sequencer可以得知消费的最慢的消费者消费到了哪个位置。
1 2 3 gatingSequences =[7 , 8 , 9 , 10 , 3 , 4 , 5 , 6 , 11 ]8 个消费者的例子,最慢的消费完了3 ,此时可以写seq 19 的数据,但不能写seq 20 (会覆盖 seq 4 的位置, 还没消费)
在next(n)方法里,如果计算出的下一个event的Sequence值减去bufferSize.得出来的 wrapPoint > min(gatingSequences),说明即将写入的位置上,之前的event还有消费者没有消费,这时SingleProducerSequencer会等待并自旋。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public long next (int n) if (n < 1 )throw new IllegalArgumentException ("n must be > 0" );long nextValue = this .nextValue;long nextSequence = nextValue + n;long wrapPoint = nextSequence - bufferSize;long cachedGatingSequence = this .cachedValue;if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)setVolatile (nextValue); long minSequence;while (wrapPoint > (minSequence = Util.getMinimumSequence (gatingSequences, nextValue)))parkNanos (1L ); this .cachedValue = minSequence;this .nextValue = nextSequence;return nextSequence;
举个例子,gatingSequences=[7, 8, 9, 10, 3, 4, 5, 6, 11], RingBuffer size 16的情况下,如果算出来的nextSequence是20,wrapPoint是20-16=4, 这时gatingSequences里最小的是3。
说明下一个打算写入的位置是wrapPoint 4,但最慢的消费者才消费到3,你不能去覆盖之前4上的数据,这时只能等待,等消费者把之前的4消费掉。
为什么wrapPoint = nextSequence - bufferSize,而不是bufferSize的n倍呢,因为消费者只能落后生产者一圈,不然就已经存在数据覆盖了。
等到SingleProducerSequencer自旋到下一个位置所有人都消费过的时候,它就可以从next方法中返回,生产者拿着sequence就可以继续去发布。
MultiProducerSequencer MultiProducerSequencer 是在多个生产者的场合使用的,多个生产者的情况下存在竞争,导致它的实现更加复杂。
相较于单生产者, 主要多出来的数据结构是 availableBuffer, 来记录RingBuffer上哪些位置有数据可以读:
1 2 3 4 5 6 7 8 9 10 11 12 int [] availableBuffer;int indexMask;int indexShift;public MultiProducerSequencer (int bufferSize, final WaitStrategy waitStrategy) super (bufferSize, waitStrategy);new int [bufferSize];1 ;
Sequencer.next(n)说起,计算下一个数据位Sequence的逻辑是一样的,包括消费者落后导致Sequencer自旋等待的逻辑。不同的是因为有多个publisher同时访问Sequencer.next(n)方法,所以在确定最终位置的时候用了一个CAS操作,如果失败了就自旋再来一次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public long next (int n)if (n < 1 )throw new IllegalArgumentException("n must be > 0" );long current;long next ;do next = current + n;long wrapPoint = next - bufferSize;long cachedGatingSequence = gatingSequenceCache.get();if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)long gatingSequence = Util.getMinimumSequence(gatingSequences, current);if (wrapPoint > gatingSequence)1 ); continue ;else if (cursor.compareAndSet(current, next ))break ;while (true );return next ;
另一个不同的地方是 publish(final long sequence) 方法,SingleProducer的版本很简单,就是移动了一下cursor:
1 2 3 4 5 public void publish(long sequence )cursor .set (sequence );
MultiProducer的版本则去设置availableBuffer的状态位了。给定一个sequence,先计算出对应的数组下标 index,然后计算出在那个index上要写的数据 availabilityFlag。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public void publish (final long sequence) setAvailable (sequence);signalAllWhenBlocking ();private void setAvailable (final long sequence) setAvailableBufferValue (calculateIndex (sequence), calculateAvailabilityFlag (sequence));private int calculateIndex (final long sequence) return ((int ) sequence) & indexMask;private int calculateAvailabilityFlag (final long sequence) return (int ) (sequence >>> indexShift);private void setAvailableBufferValue (int index, int flag) long bufferAddress = (index * SCALE) + BASE;putOrderedInt (availableBuffer, bufferAddress, flag);
availableBuffer 主要用于判断一个 sequence 下的数据是否可用, MultiProducerSequencer 的 isAvailable:
1 2 3 4 5 6 7 public boolean isAvailable(long sequence )int index = calculateIndex(sequence );int flag = calculateAvailabilityFlag(sequence );index * SCALE ) + BASE;return UNSAFE.getIntVolatile(availableBuffer, bufferAddress) == flag;
SingleProducerSequencer 的方法如下:
1 2 3 4 public boolean isAvailable(long sequence )return sequence <= cursor .get ();
在单个生产者的场景下,publishEvent的时候才会推进 cursor,所以只要 sequence<=cursor,就说明数据是可消费的。
多个生产者的场景下,在next(n)方法中,就已经通过 cursor.compareAndSet(current, next) 移动cursor了,此时event还没有publish,所以cursor所在的位置不能保证event一定可用。
在publish方法中是去setAvailable(sequence)了,所以 availableBuffer 是数据是否可用的标志。那为什么值要写成圈数呢,应该是避免把上一轮的数据当成这一轮的数据,错误判断sequence是否可用。
消费者 当调用 disruptor.handleEventsWith 设置消息的处理器时,Event Handler 会被包装为 BatchEventProcessor.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)return createEventProcessors(new Sequence [0 ], handlers);final Sequence[] barrierSequences,final EventHandler<? super T>[] eventHandlers)final Sequence[] processorSequences = new Sequence [eventHandlers.length];final SequenceBarrier barrier = ringBuffer.new Barrier (barrierSequences);for (int i = 0 , eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)final EventHandler<? super T> eventHandler = eventHandlers[i];final BatchEventProcessor<T> batchEventProcessor =new BatchEventProcessor <T>(ringBuffer, barrier, eventHandler);if (exceptionHandler != null )return new EventHandlerGroup <T>(this , consumerRepository, processorSequences);
Disruptor 启动后消费过程:
EventProcessor EventProcessor extends Runnable 可以理解为是一个消费者线程的接口.
主要实现类是 BatchEventProcessor, 主要属性是
1 2 3 4 DataProvider<T> dataProvider; ; ; Sequence sequence = new Sequence (-1 );
run 方法中processEvent是主要的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 private void processEvents ()event = null ;long nextSequence = sequence.get () + 1L ;while (true )try long availableSequence = sequenceBarrier.waitFor(nextSequence);if (batchStartAware != null )1 );while (nextSequence <= availableSequence)event = dataProvider.get (nextSequence);event , nextSequence, nextSequence == availableSequence);set (availableSequence);catch (final TimeoutException e)get ());catch (final AlertException ex)if (running.get () != RUNNING)break ;catch (final Throwable ex)event );set (nextSequence);
SequenceBarrier BatchEventProcessor.processEvent 会先调用 sequnceBarries.waitFor 等待事件的产生。 SequnceBarries 的实现类是 ProcessingSequenceBarrier
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public long waitFor (final long sequence) throws AlertException, InterruptedException, TimeoutException long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this );if (availableSequence < sequence)return availableSequence;return sequencer.getHighestPublishedSequence (sequence, availableSequence)
拿到的availableSequence可能比要求的nextSequence大,意味着生产者生产出了很多可以消费的 event。这时就会一个个去消费,并且更新BatchEventProcessor的sequence至availableSequence。此时Sequencer上的gatingSequences因为是引用的关系也会被更新。
WaitStrategy 调用 sequenceBarrier.waitFor(nextSequence) 时可能不会立即有新的event,这时的行为由 waitStrategy 决定,有多种实现,比如 BlockingWaitStrategy。
Sequencer在构造的时候就会传入一个 waitStrategy,sequenceBarrier 是由 Sequencer 创建的,创建的时候把 Sequencer 的 waitStrategy 传递给 sequenceBarrier。Sequencer和SequenceBarrier持有同样的waitStrategy,相当于在两者间起到了 传递信息和回调 的作用。
消费者在没有可消费的event时会调用waitStrategy.waitFor陷入等待,生产者会在生产出新event后调用waitStrategy.signalAllWhenBlocking来唤醒消费者。
不同的 WaitStrategy 的实现会有不同的效率和性能。
BlockingWaitStrategy: 该实现依赖Lock来设置等待和唤醒。 系统吞吐量和低延迟的表现比较差,好处是对CPU的消耗比较少。
1 2 3 4 5 6 7 8 Lock lock = new ReentrantLock()= lock.newCondition()
SleepingWaitStrategy: 该实现是在性能和CPU占用之间的一种折中。该实现对负责调用唤醒方法的生产者比较友好,因为啥都不用做。相当于完全依赖消费者端的自旋retry。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 inal int DEFAULT_RETRIES = 200 ;long DEFAULT_SLEEP = 100 ;int retries;long sleepTimeNs;if (counter > 100 )else if (counter > 0 ) else
YieldingWaitStrategy: 该实现和SleepingWaitStrategy很类似,只是它在等待的时候会吃掉100%的CPU。
1 2 3 4 5 6 7 8 9 // 等待的实现, 只有 counter= = 0 的时候才让出CPU,其他时候都在自旋。 0 = = counter)
BusySpinWaitStrategy: 该实现的唤醒也是啥都不做。性能最好的实现,但对部署环境的要求也最高。消费者线程数应该要少于CPU的实际物理核心数。
1 2 .onSpinWait ();
WorkerPool 1 2 Sequence workSequence = new Sequence (-1 );
WorkerPool 内部维护了一个 workSequence,代表着整个pool分配出去的event位置。
WorkProcessor WorkProcessor 是基本的消费者线程,它保有workSequence的引用。
在它的run loop中,它会首先尝试CAS去抢 workSequence 的下一个位置,抢到了就会去消费。
如果没有可消费的event了,它就会调用 sequenceBarrier.waitFor(nextSequence) 陷入等待。但即使有了新的event被唤醒,它还是要靠CAS去抢下一个event的消费权。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 while (true )try if (processedSequence) false ;do get () + 1L ; set (nextSequence - 1L ); while (!workSequence.compareAndSet(nextSequence - 1L , nextSequence));if (cachedAvailableSequence >= nextSequence) event = ringBuffer.get (nextSequence);event );true ;else