docker网络原理
Docker 网络架构
目前围绕着 docker 的网络,目前有两种比较主流的声音,docker主导的 Container network model(CNM) 和社区主导的 Container network interface(CNI)
CNI(Container Networking Interface)架构
CNI(Container Networking Interface)提供了一种linux的应用容器的插件化网络解决方案。
CNI本身并不完全针对docker的容器,而是提供一种普适的容器网络解决方案。因此他的模型只涉及两个概念:
- 容器(container) : 容器是拥有独立linux网络命名空间的独立单元。比如rkt/docker创建出来的容器。 这里很关键的是容器需要拥有自己的linux网络命名空间。这也是加入网络的必要条件。
- 网络(network): 网络指代了可以相互联系的一组实体。这些实体拥有各自独立唯一的ip。这些实体可以是容器,是物理机,或者其他网络设备(比如路由器)等。
CNI接口设计非常简单只有 Add(NetworkToContainer)/Delete 两个接口
CNM(Container Network Model) 架构
CNM 是docker公司力推的网络模型, 模型如下:
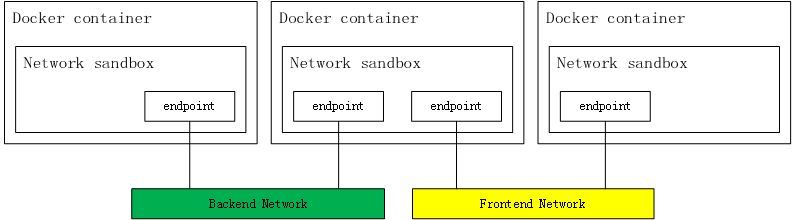
其中三个组成要素:
- 沙盒(sandbox): 是一种独立的网络栈,包括以太网接口,端口,路由以及DNS配置
- 终端(endpoint): 虚拟网络接口,负责创建连接,将沙盒连接到网络
- 网络(network):网桥的软件实现
Docker 中的网络
docker 对 CNM 的实现
其中 libnetwork 是 CNM 的标准实现, 支持跨平台,3个标准的组件和服务发现,基于Ingress的容器负载均衡,以及网络控制层和管理层的功能:
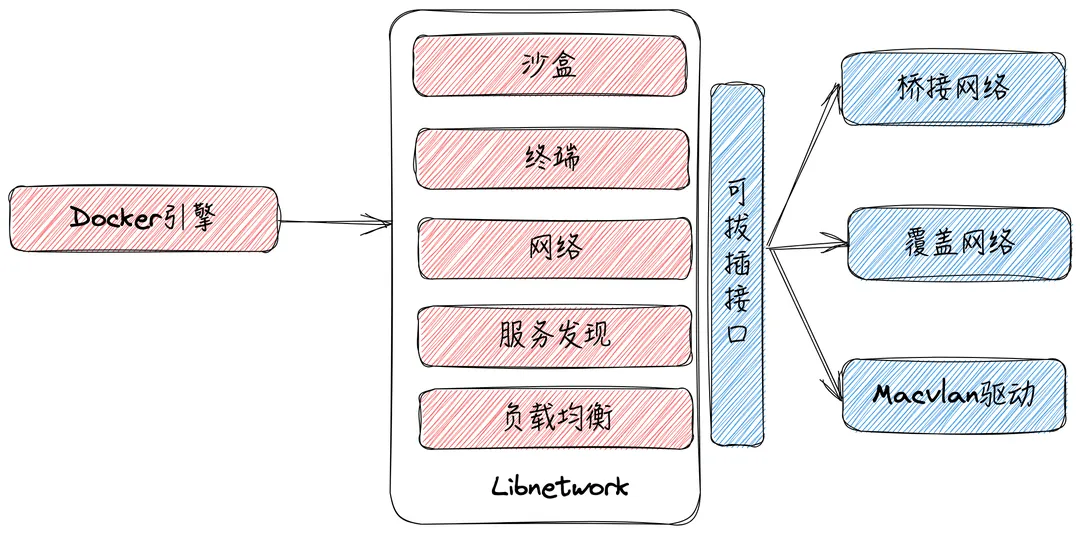
网络模式
- 网桥(Bridge): 容器通过一对 veth pair 连接到 docker0 网桥上,由Docker为容器动态分配IP及配置路由、防火墙规则等, 也是 docker 默认的网络实现。
- Host :容器与主机共享同一Network Namespace,共享同一套网络协议栈、路由表及iptables规则等,执行
docker run --net=host centos:7 python -m SimpleHTTPServer 8081,然后查看看网络情况(netstat -tunpl) :从上可以看出host模型下,和主机上启动一个端口没有差别,也不会做端口映射,所以不同的服务在主机端口范围内不能冲突1
2
3
4
5
6
7[root@VM-240-187-centos ~]# netstat -lnptu
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
--- 这个是用默认的 bridge 模式启动的, 可以看到进程是 docker-proxy
tcp 0 0 0.0.0.0:18000 0.0.0.0:* LISTEN 8782/docker-proxy
--- 用 host 模式启动的, 跟主机启动一个进程占用端口没有区别
tcp 0 0 0.0.0.0:8081 0.0.0.0:* LISTEN 1220865/python - Overlay:多机覆盖网络是Docker原生的跨主机多子网网络方案,主要通过使用
Linux bridge和vxlan隧道实现,底层通过类似于etcd或consul的KV存储系统实现多机的信息同步 - Remote:Docker网络插件的实现,可以借助
Libnetwork实现网络自己的网络插件 - None:模式是最简单的网络模式,它会使得Docker容器完全隔离,无法访问外部网络。在None模式下,容器不会被分配IP地址,也无法与其他容器和主机通信,可以尝试执行
docker run --net=none centos:7 python -m SimpleHTTPServer 8081,然后本机 curl 一下应该是无法访问的
网桥 Bridge
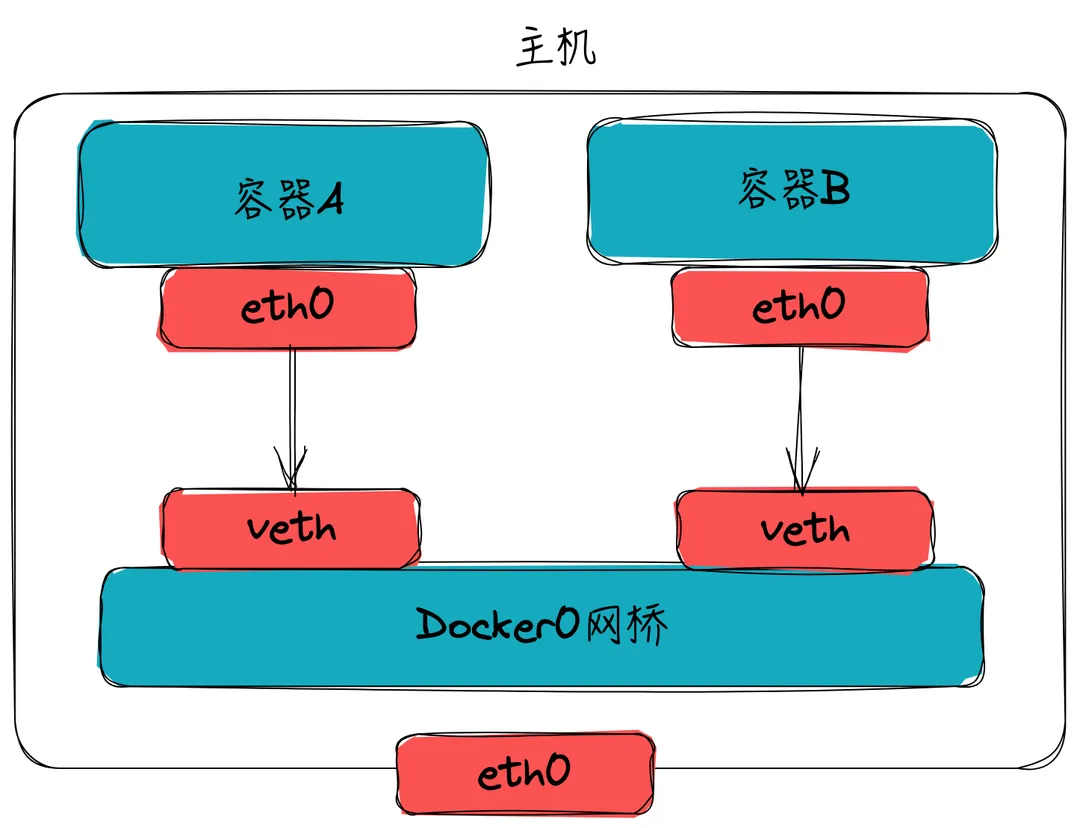
网桥 tap/tun、veth-pair一样,网桥是一种虚拟网络设备,所以具备虚拟网络设备的所有特性,比如可以配置IP、MAC等,除此之外,网桥还是一个二层交换机,具有交换机所有的功能
Docker daemon 启动时会在主机创建一个Linux网桥(默认为docker0),容器启动时,Docker会创建一对veth-pair(虚拟网络接口)设备,veth设备的特点是成对存在,从一端进入的数据会同时出现在另一端,Docker会将一端挂载到docker0网桥上,另一端放入容器的Network Namespace内,从而实现容器与主机通信, 如下:
查看网桥信息
查看本机上 docker 的网络 docker network ls:
1 | |
其他几个字段好理解, 需要注意的是 SCOPE 代表网络作用范围: 可以是 local(本地)、global(全局)或 swarm(集群)
查看网桥的详细信息 docker inspect bridge, 在 Containers 字段可以看到使用 bridge 的容器详细网络信息 IPv4Address,MacAddress和EndpointID:
1 | |
需要注意的是, 我们可以看到容器的 IPv4Address 是一个网段的表示, 这也代表容器的ip会动态分配到这个网段, 容器之间能够互相通信
网桥的数据连通
上面我们说到 bridge 模式是基于一个CIDR网段分配的, 在该网段内是可以连通的, 譬如我进入到 redis 容器(ip 是 172.117.0.3)里面去 ping 另外一个容器:
1 | |
看出来, 的确容器之间是可以互通
基于上面我们已经了解容器与容器之间的通讯,那么Docker端口映射是如何通讯的呢
在主机上执行 iptables -t nat -nvL 查看防火墙 NAT 规则转换表可以看到:
1 | |
在这里先说明一下 iptables -t nat 的输出:
- Chain:规则所属的链,如
- PREROUTING: 在数据包到达路由决策之前对其进行处理。这通常用于目的地址转换(DNAT),将数据包的目标地址更改为本地网络中的某个主机
- POSTROUTING: 在数据包离开路由决策之前对其进行处理。这通常用于源地址转换(SNAT),将数据包的源地址更改为本地网络中的某个主机
- INPUT: 处理到达本机的数据包
- OUTPUT: 处理从本机发出的数据包
- CUSTOM: 用户自定义的 chain, 用于实现特定的地址过滤以及转换, 如上述的 DOCKER
- in/out: 入站/出站流量
- source/destination: 源地址/目的地址
- target: 规则的目标动作,如 DNAT、SNAT 或 ACCEPT 等。上面有
MASQUERADE代表源地址伪装(Source Address Masquerade)
然后从上述路由规则可以看出: 只要是非docker0进来的数据包(如eth0进来的数据),都是 16379 直接转到 172.17.0.3:6379,可以看出这里是借助 iptables 实现的。
总结一下整个网桥模式下的 docker 网络流程:
- 容器与容器之前通讯是通过
Network Namespace,bridge和veth pair这三个虚拟设备实现一个简单的二层网络,不同的 namespace 实现了不同容器的网络隔离让他们分别有自己的ip,通过veth pair连接到docker0网桥上实现了容器间和宿主机的互通; - 容器与外部或者主机通过端口映射通讯是借助 iptables,通过路由转发到 docker0,容器通过查询 CAM 表,或者 UDP 广播获得指定目标地址的 MAC 地址,最后将数据包通过指定目标地址的连接在 docker0 上的 veth pair 设备,发送到容器内部的 eth0 网卡上;
- 容器与外部或者主机通过端口映射通讯对应的限制是相同的端口不能在主机下重复映射
Overlay
Overlay 指的就是在物理网络层上再搭建一层网络,通过某种技术再构建一张相同的逻辑网络。 这里需要注意的是 overlay 模式, 是需要再 Docker Swarm(集群)环境下创建的
在介绍 overlay 之前, 首先讲一下 VXlan(Visual eXtensible Local Area Network): 通过 VXLAN 技术可以实现在已有三层网络上构建虚拟二层网络,实现主机之间的二层互通。
VXLAN 的工作原理基于隧道封装技术,将二层的以太网帧(Ethernet frames) 封装成四层的 UDP数据报(datagrams)(所以 VXLAN 也称为 mac in udp),然后在 L3 的网络中传输,效果就像L2的以太网帧在一个广播域中传输一样,实际上是跨越了L3网络,但却感知不到L3网络的存在。具体来说,VXLAN 将二层以太网帧封装在四层 UDP 数据包中,通过源 VTEP(VXLAN Tunnel Endpoint)和目标 VTEP 之间的虚拟隧道进行传输:
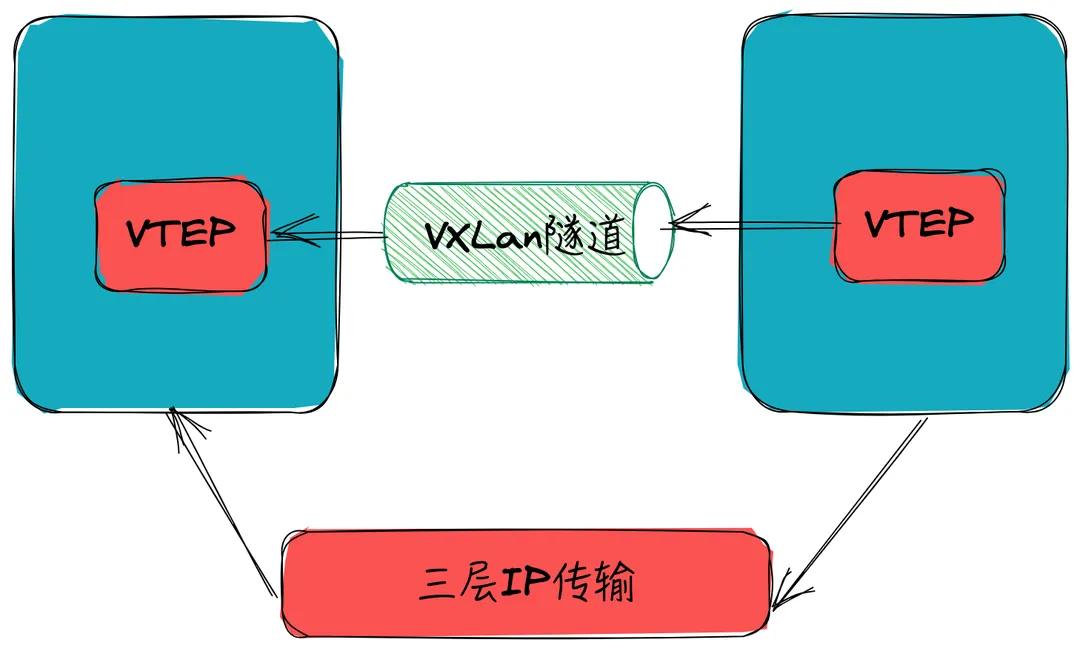
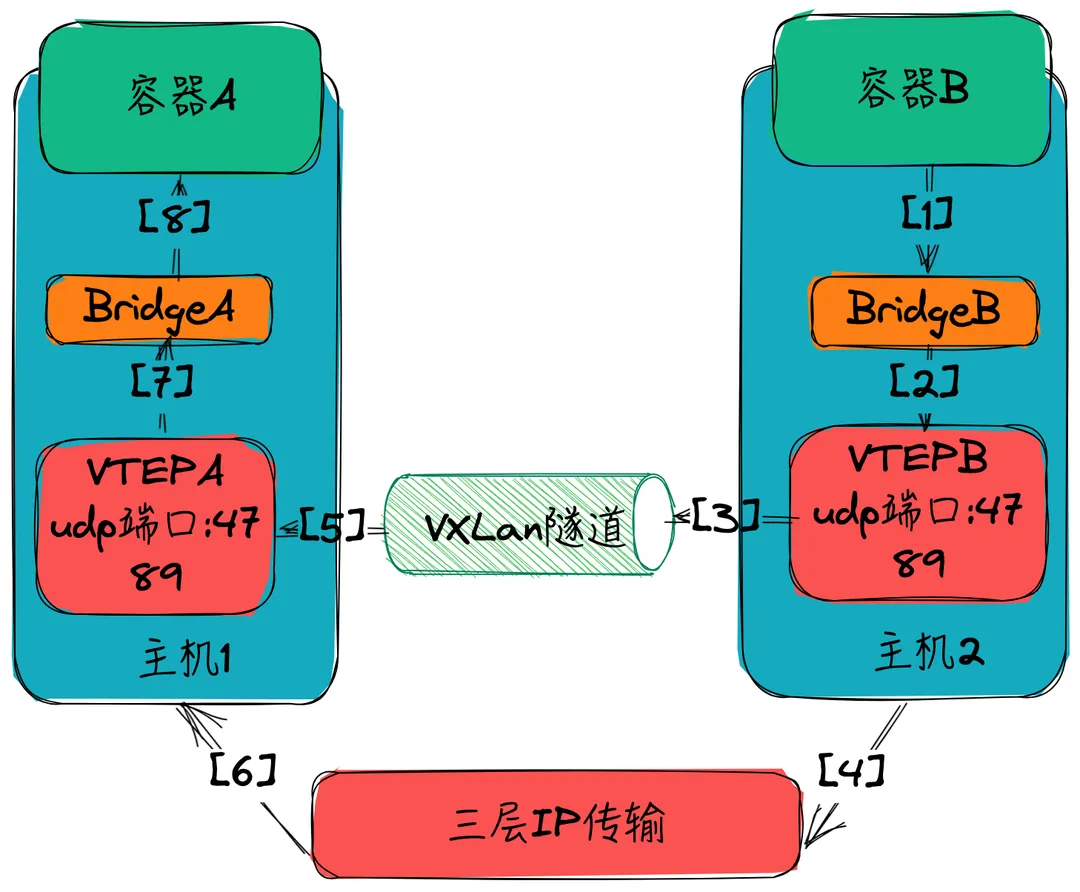
overlay 模式基于 vxlan 两个容器之间互相通信的流程如下:
- 容器B执行ping,流量通过 BridgeA 的 veth 接口发送出去,但是这个时候 BridgeB 并不知道要发送到哪里(BridgeB没有MAC与容器A的IP映射表),所以 BridgeB 将通过 VTEP 解析 ARP 协议,确定 MAC 和 IP 以后,将真正的数据包转发给 VTEP,带上 VTEP 的 MAC 地址
- VTEP-B收到数据包,通过Swarm的集群的网络信息中知道目标IP是容器B
- VTEP-B将数据包封装为VXLAN格式(数据包中存储了VXLAN的ID,记录其映射关系)
- 实际底层VTEP-B将数据包通过主机B的UDP物理通道将VXLAN数据包封装为UDP发送出去
- 通过隧道传输(UDP端口:4789)
- 数据包到达VTEP-A,VTEP-A解析数据包读取其中的VXLAN的ID,确定发送到哪个网桥
- VTEP-A继续解包和封包,将数据从UDP中拆解出来,重新组装网络协议包,发送给BridgeA
- BridgeA收到数据,通过veth发给容器A,回包的过程就是反向处理
整个流程如下: