ES快照原理
ES Snapshot 快照 概览
快照模块是 ES 备份、迁移数据的重要手段。ES 快照支持增量备份,支持多种类型的仓库存储。
仓库用于存储快照,支持共享文件系统(例如 nfs),以及通过插件支持的HDFS、Amazon S3、Microsoft Azure、Google GCS。譬如云上对象存储:
repository 相关 API
1. 创建 repository 快照仓库
1 | |
这里 fs 代表快照仓库的类型是一个共享文件系统, 可以有其他类型如 s3、oss、cos 等, 需要对应插件支持。 settings 代表配置项目, 通常支持:
compress: 是否开启压缩。压缩仅对元数据进行(mapping 及 settings),不对数据文件压缩。默认为 truechunk_size: 传输文件时数据被分解为块,此处配置块大小,单位为字节max_snapshot_bytes_per_sec: 快照操作时节点间限速值,默认 40mb(ES 7.8)max_restore_bytes_per_sec: 从快照恢复时节点间限速值,默认40mb(ES 7.8)readonly: 设置仓库属性为只读。默认为 false
2. 查看仓库信息
以下命令可以查看某个仓库的具体信息
1 | |
查看全部仓库信息: curl -X GET "localhost:9200/_snapshot/_all"
Snapshot 相关 API
1.创建快照
命令: curl -X PUT "localhost:9200/_snapshot/my_backup/snapshot_1?wait_for_completion=true"
这里 wait_for_completion 参数是可选项,默认情况下,快照命令会立即返回,任务在后台执行。如果想要等待任务完成 API 才返回,可以将 wait_for_completion 参数设置为 true。默认为 false。
如果想对部分索引执行快照,可以在请求的 indices 参数中指定:
1 | |
indices: 部分索引筛选, 字段支持多索引语法,例如:index_*ignore_unavailable: 跳过不存在的索引。默认 false, 因此默认情况下遇到不存在的索引快照失败include_global_state: 不快照集群状态 。默认 false 。注意,集群设置和模板保存在集群状态中,因此默认情况下不快照集群设置和模板,但是一般情况下我们需要将这些信息一起保存
快照操作在主分片上执行。快照执行期间,不影响正常的读写操作。
在快照开始前,会执行一次 flush,将操作系统内存 cache 的数据刷盘。因此快照的数据是从快照时间点开始磁盘中存储的 lucene 数据,不包括后续的新增内容。但是 每次的快照过程是增量的,下一次快照只会包含新增内容
需要注意的是, 快照可以在集群 green,yellow 或 red 的时候进行, 当时执行快照期间, 被快照的节点不能移动到另一个节点, 这种分片迁移只可以在快照完成时进行
2. 获取快照信息
命令: curl -X GET "localhost:9200/_snapshot/my_backup/snapshot_1" , 返回的信息大概如下:
1 | |
主要是开始结束时间、集群版本、当前阶段、成功及失败情况等基本信息。快照执行期间会经历以下几个阶段:
- IN_PROGRESS: 快照正在运行。
- SUCCESS: 快照创建完成,并且所有分片都存储成功。
- FAILED: 快照创建失败,没有存储任何数据。
- PARTIAL: 集状态全局状态已储存,但至少有一个分片的数据没有存储成功。在返回的failure字段中包含了相关未正确处理分片的详细信息。
- INCOMPATIBLE: 快照与当前集群版本不兼容。
获取指定仓库下所有快照信息: curl -X GET "localhost:9200/_snapshot/my_backup/_all"
3. 查看快照状态
命令: curl -X GET "localhost:9200/_snapshot/_status", 返回的信息如下:
1 | |
这里的信息主要是已处理的文件数和字节数等信息
4. 删除快照
DELETE _snapshot/my_backup/snapshot_3
删除指定的快照。如果该快照正在进行,执行删除 API,系统会中断快照进程并删除仓库中创建到一半的快照。
5. 恢复快照
从快照中恢复需要注意:
- 建议不要恢复.开头的系统索引,此操作可能会导致Kibana访问失败。
- 如果集群中存在与待恢复索引同名的索引,需要提前删除或者关闭该同名索引后再恢复,否则恢复失败。
恢复指令:
1 | |
6. 查看快照恢复信息
查看快照指定索引的恢复状态:
1 | |
查看集群中的所有索引的恢复信息
1 | |
ES节点文件结构与lucene快照
ES 的内核本质上是 lucene 框架, 一个分片即是一个 lucene 对象实例。ES snapshot 快照本质是对 lucene 物理文件的拷贝。
我们先看看数据文件是如何组织的, 在 ES 节点上, 数据目录文件结构如下:
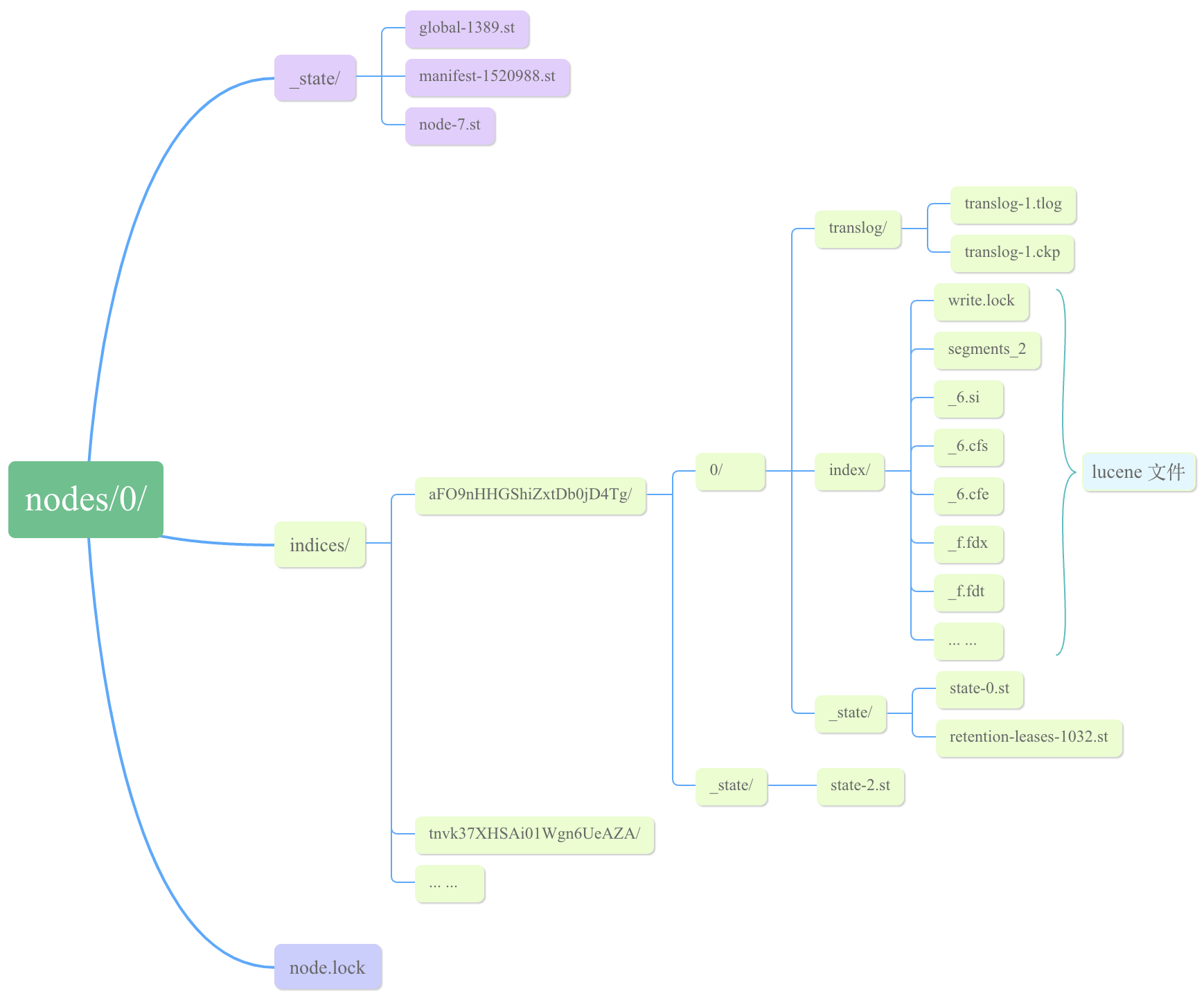
- node.lock: 为了避免集群数据目录冲突,
node.lock文件可以确保一次只能从一个数据目录读取/写入一个 ES 相关的安装启动信息。 - _state 目录: 存储着集群状态以及集群分片映射等信息
- indices: 存储索引文件数据,
index文件夹由 lucene 写入,translog文件夹和_state文件夹由 ES 写入。lucene 每次添加/修改的数据先放在内存中,并不是实时落盘的,而是直到缓冲区满了或者用户执行 commit api,数据才会落盘,形成一个 segement,保存在文件中。ES 节点实现了 translog 类, 即数据索引前,会先写入到日志文件中。translog 用于在节点机器突发故障(比如断电或者其他原因)导致节点宕机,重启节点时就会重放日志,这样相当于把用户的操作模拟了一遍。保证了数据的不丢失。节点宕机重启后并非重放所有的 translog,而是最新没有提交索引的那一部分。所以必须有一个 checkpoint, 即 translog.ckp 文件,保证节点宕机重启后可以从最近已提交的文件处重放,类似 bin log 的 positio - index: index 文件是由 lucene 维护的, Lucene快照是对最后一个提交点的快照,一次快照包含最后一次提交点的信息,以及全部分段文件。因此这个快照实际上就是对已刷盘数据的完整的快照。注意Lucene中没有增量快照的概念。每一次都是对整个Lucene索引完整快照,它代表这个Lucene索引的最新状态。
总的来说:
Lucene 快照负责获取最新的、已刷盘的分段文件列表,并保证这些文件不被删除,这个文件列表就是ES要执行复制的文件。
ES负责数据复制、仓库管理、增量备份,以及快照删