计算机存储设计理论
概述
不同的数据库存储系统都会设计不同的索引结构来优化查询/写入效率, 在讨论这些结构之前, 我们先从头回顾一下计算机存储的一些设计
计算机存储分级设计
计算机的存储器设计采用了一种分层次的结构。寄存器、高速缓存、主存和硬盘,从顶至底,这些存储器的速度逐级递减而容量逐级递增,并且伴随越来越低的价钱,如图
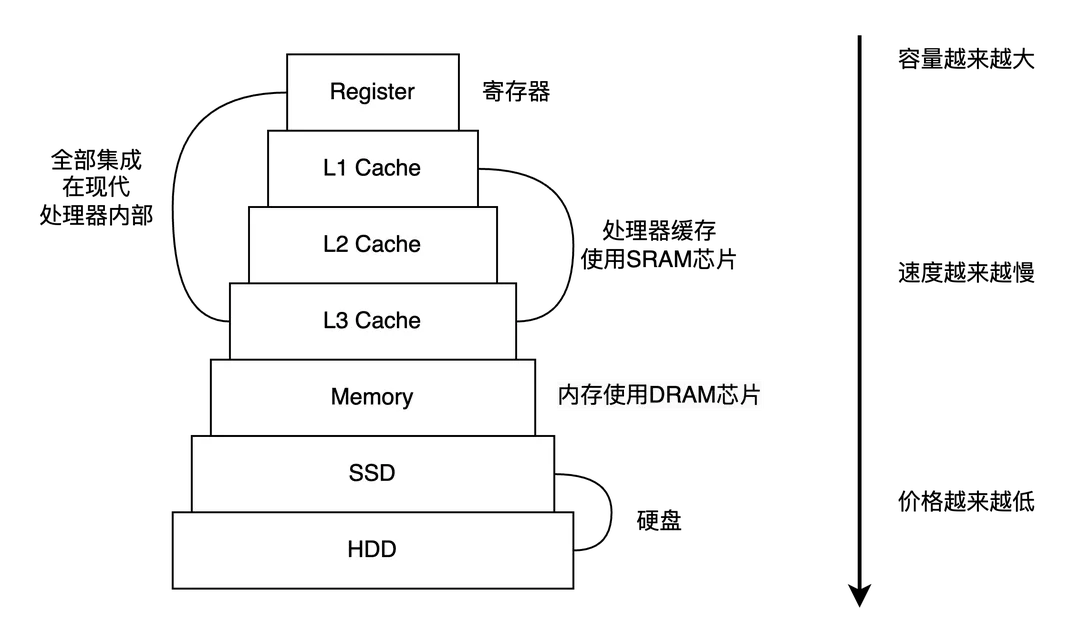
在现代计算机里面, 上面的存储实际上分为CPU(寄存器,高速缓存L1、L2、L3)、内存、硬盘(SSD,HDD)
IO 局部性原理
局部性原理(Principle of Locality)指在程序执行过程中,倾向于访问某些局部特定的数据或指令,而不是随机地访问整个内存空间。通常分为两种类型:时间局部性和空间局部性。
- 时间局部性(Temporal Locality):如果一个数据被访问,那么在近期内它很可能会被再次访问。例如,在一个循环中反复使用的变量
- 空间局部性(Spatial Locality):如果一个数据项被访问,那么在其附近的数据项也很可能会被访问。例如,顺序执行的指令和顺序访问的数组元素
page cache
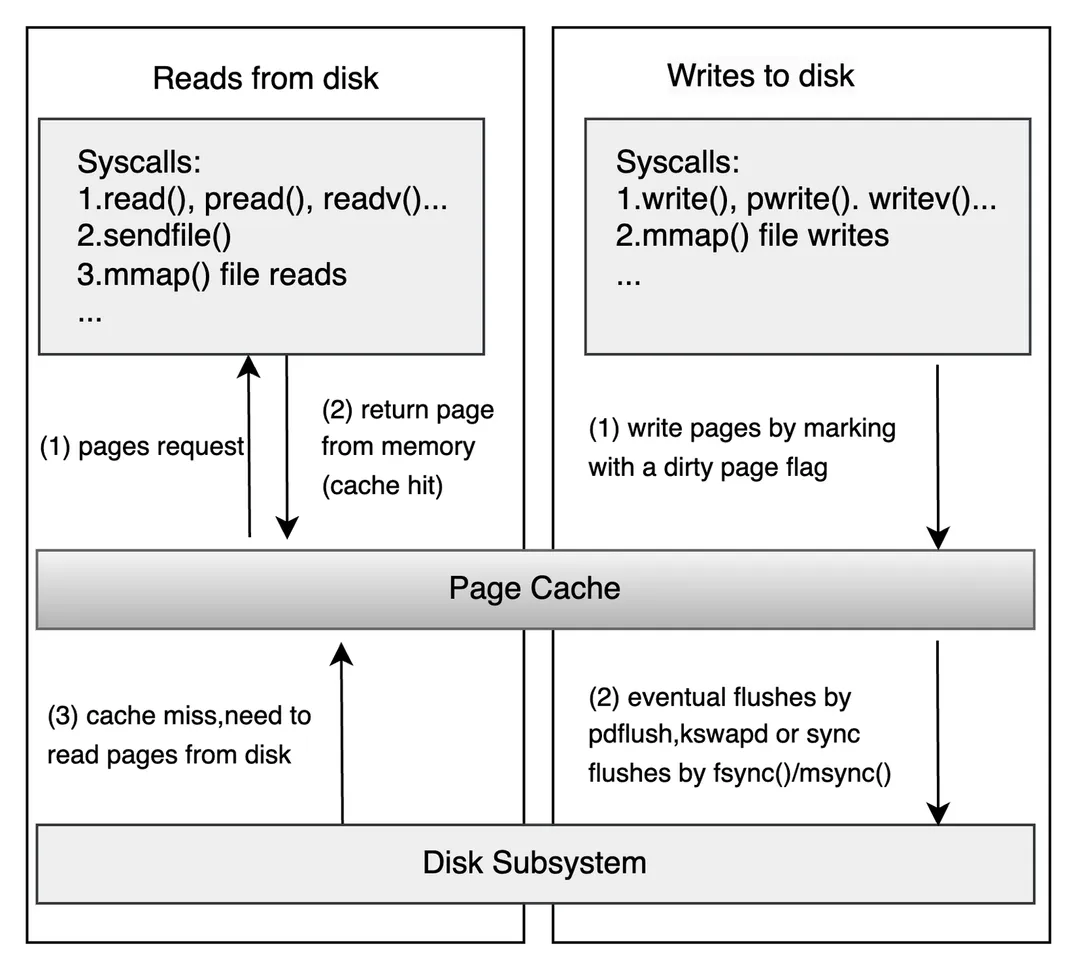
系统调用的read/write和底层的硬盘读写之间存在一层I/O缓存(Kernel buffer cache),在Linux中称为Page Cache,它利用了局部性原理来提高系统的I/O性能:
- 当一个数据页被从硬盘读取到内存时,它被存储在
Page Cache中。如果这个数据页在近期内被再次访问(时间局部性),那么可以直接从 Page Cache 中读取,而无需再次访问硬盘。 - 当一个数据页被读取时,操作系统通常会预读取一些附近的数据页(空间局部性),并将它们也存储在
Page Cache中,以便后续的访问。
Page Cache的大小是根据当前系统的可用内存和工作负载动态调整的,此外还会通过页面置换算法如 LRU 定期淘汰旧的数据页。Page Cache可以大大减少硬盘I/O,从而提高系统的性能。
Page Cache支持写回(write-back)和写穿(write-through)两种策略:
- 在写回策略中,当程序写入数据时,数据首先被写入Page Cache,然后在适当的时机被写入硬盘。
- 在写穿策略中,数据同时被写入Page Cache和硬盘。
Linux下默认使用 write-back 策略,即文件操作的写只写到 Page Cache 就返回。Page Cache中被修改的内存页称之为脏页(Dirty Page),脏页在特定的时候被一个叫做pdflush(Page Dirty Flush)的内核线程写入硬盘,写入的时机和条件如下:
- 当空闲内存低于一个特定的阈值时
- 当脏页在内存中驻留时间超过一个特定的阈值时
- 用户进程调用sync、fsync、fdatasync系统调用时
顺序 IO
顺序I/O(Sequential I/O)是一种数据访问模式,其中数据按照连续的顺序进行读取或写入。这与随机I/O(Random I/O)形成对比,随机I/O是指数据的访问位置在存储设备上是随机分布的。
顺序I/O的性能之所以高,主要是因为它能够最大化利用存储设备的局部性原理,并且减少了寻道时间和旋转延迟:
- 局部性原理:在顺序I/O中,数据是连续读取或写入的,Page Cache可以将文件的连续数据块缓存在内存中,以提供快速的连续读取。此外Page Cache可以将内存中缓存的连续数据,比如按页大小批次刷新到硬盘。这样可以减少频繁的硬盘写入操作。
- 减少寻道时间和旋转延迟:寻道操作指磁头移动到硬盘的正确轨道的过程,旋转延迟指磁头等待硬盘旋转到正确位置的时间。在顺序I/O中,由于数据是连续存储的,因此可以大大减少寻道时间和旋转延迟,从而提高I/O性能。
内存访问速度和硬盘访问速度的对比结果。简单总结下:
- 硬盘访问时间:寻道时间+旋转时间+传输时间:
- 硬盘随机I/O ≪ 硬盘顺序I/O ≈ 内存随机I/O≪ 内存顺序I/O。
- 机械硬盘和固态硬盘构成:
- 机械硬盘:电磁存储,通过电磁信号转变来控制读写,磁头机械臂移动;
- 固态硬盘:半导体存储,用固态电子存储芯片阵列、由控制单元和存储单元组成,内部由闪存颗粒组成。速度较快
访问速度对比:
存储引擎
存储引擎是存储系统的发动机,决定了存储系统的性能和功能。存储引擎主要负责数据如何读写,包括读多写少和写多读少场景,读取操作又分为随机读取和顺序扫描。目前常见的存储引擎使用的存储数据结构主要有:
- 哈希表(Hash Table):支持随机读取,但不支持顺序扫描,对应键值 (Key-Value) 存储系统
- B 树(Balance Tree): 适用于那些需要快速查找、插入和删除关键字的场景,如文件系统、数据库等。
- B+树(Balance+ Tree):支持随机读取和顺序扫描,读多写少场景,用于那些需要高效进行范围查询和顺序访问的场景,如数据库、索引等
- LSM树(Log-Structured Merge Tree):支持随机读取
Hash table
mysql 在指定索引的时候可以使用 B+Tree 或 HashTable。
由于哈希映射关系,哈希表在查找单条数据时候,能保证O(1)的时间复杂读。但哈希表在范围查询和排序遍历时候,只能进行全表扫描并依次判断是否满足条件,这样就会让性能影响非常大, 所以不是特殊场景(譬如 Memory 引擎)不会选择 HashTable 当做底层存储结构
B Tree
相较于 HashTable 查找的平均时间复杂度比O(1)稍慢的是O(logn),这类数据结构有 **平衡二叉树(AVL Tree),红黑树(RB Tree)、B树(B Tree)、B+树(B+ Tree)**等。此类型结构天然就支持排序、范围查找操作。
以平衡二叉树为例,一般情况下查询性能非常好,但平衡二叉树单个节点只能保存一个数据,因此当覆盖大量数据时候,平衡二叉树的树高度很高。这意味着当需要通过遍历获取存储在硬盘上的数据时候,需要更多次的I/O操作。硬盘读取时间远远超过数据在内存中比较的时间,这将导致程序大部分时间会阻塞在硬盘 I/O 上。
为了降低树的高度, 减少 I/O 操作, 可以选择多叉树。
B树是一种多叉树, 每个节点都存放着索引和数据, 相比与平衡二叉树, 每个节点能够容纳更多的键值数据, 减少树的高度和硬盘访问次数。
B+Tree
B+树是B树的一种变种,它与B树的区别是:
叶子节点保存了完整的索引和数据,而非叶子节点只保存索引值。所以查询索引数据,必须要遍历到叶子节点才能取到,因此查询时间固定为 O(logn)。
另外一点是, B+tree 的叶子节点会有一个指针指向下一个叶子节点, 这让所有的叶子节点用单链表的方式连通了起来, 这样对于范围查询来说非常方便, 能够最大程度的利用 pagecache 和预读机制
相较于B Tree, B+ Tree 的高度会更矮, 范围查询的时间也会稳定一些。
相比于数据读取场景,B+树在写多场景的性能并不理想。这主要原因是:B+树在插入和删除操作时,可能需要进行节点的分裂和合并,以保持树的平衡。这会导致更新硬盘上多个数据页和Page Cache页缓存数据失效,这些操作伴随大量的随机I/O,限制B+树的写入效率。
LSM Tree
RocksDB 的核心数据结构被称为日志结构合并树 (Log Structured Merge Tree,LSM Tree),LSM树是一种专为写密集型工作负载设计的数据结构。
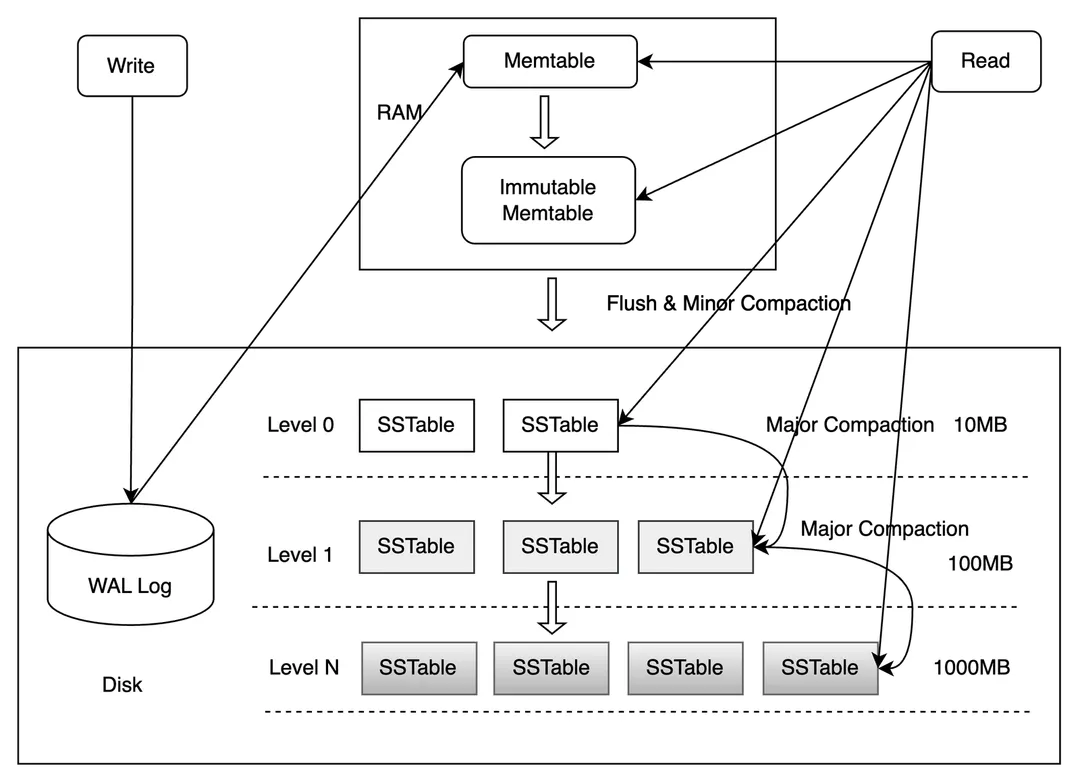
如上图, LSM树主要分为四个部分:
- MemTable: MemTable 是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据(这里key 有序主要是为了后面方便合并数据, 相同的key如果有序则可以使用归并的思想, 加快合并效率)
- Immutable MemTable:Immutable MemTable 是将转 MemTable 变为 SSTable 的一种中间状态。写操作由新的 MemTable 处理,在转存过程中不阻塞数据更新操作
- WAL:因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过预写式日志(Write-ahead logging,WAL)的方式来保证数据的可靠性。 WAL是一个只允许追加(Append Only)的文件,包含一组更改记录序列。每个记录包含键值对、记录类型(Put / Merge / Delete)和校验和(checksum)。与 MemTable 不同,在 WAL 中,记录不按 key 有序,而是按照请求到来的顺序被追加到 WAL 中
- SSTable(Sorted String Table):SSTable是一种拥有持久化,有序且不可变的的键值存储结构,它的key和value都是任意的字节数组,并且了提供了按指定key查找和指定范围的key区间迭代遍历的功能
LSM 数据写入流程
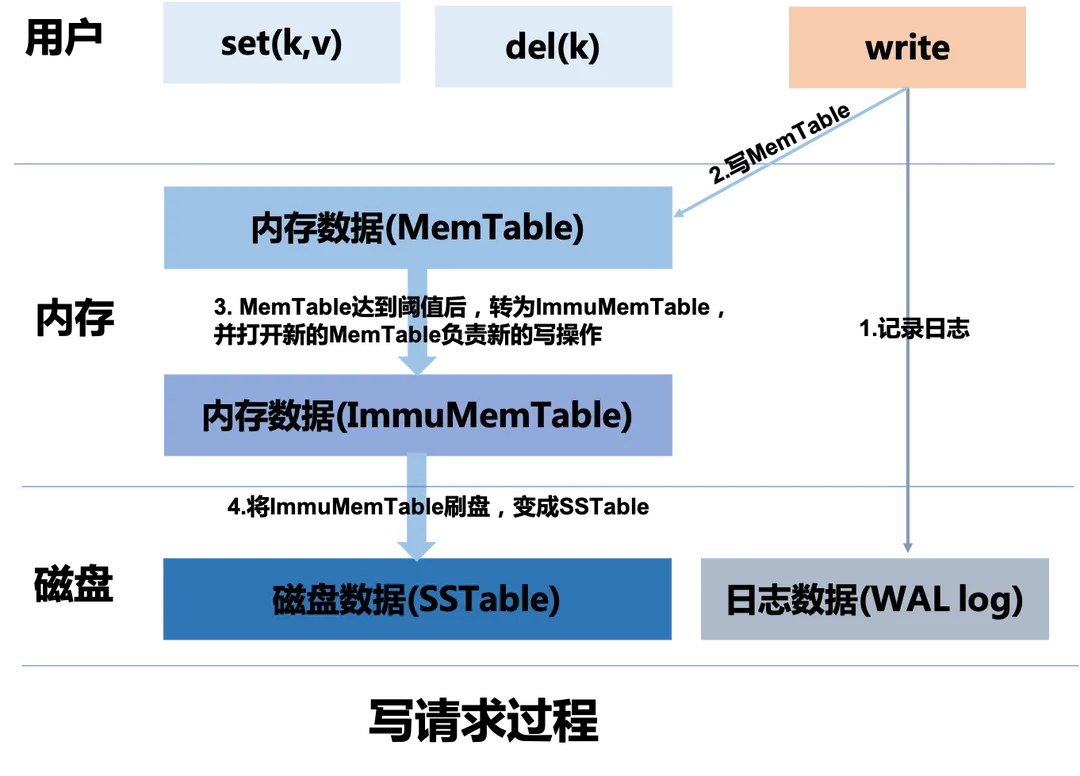
LSM 写入流程如上图:
- 首先记录到WAL log文件中;
- 接着记录到MemTable中;
- 当 MemTable 达到一定阈值后关闭该 MemTable,变成 ImmuMemTable(只读);然后打开新的 MemTable 处理写操作,将 ImmuMemTable 写入到磁盘中,形成一个 SSTable
由于 SSTable 不可修改,在不同的 SSTable 中,可能存在相同 Key 的记录,当然最新 SSTable 的那条记录才是准确的。这样的设计虽然大大提高了写性能,但同时也会带来一些问题:
- 空间放大(Space Amplification) :占用的硬盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的(例如对同一个key的add、del、update 操作只需要关注最后的结果)。
- 读放大(Read Amplification) :实际读取的数据量大于真正的数据量。例如在 LSM 树中需要先在 MemTable 查看当前 key 是否存在,不存在继续从 SSTable 中寻找。
LSM 数据读取流程
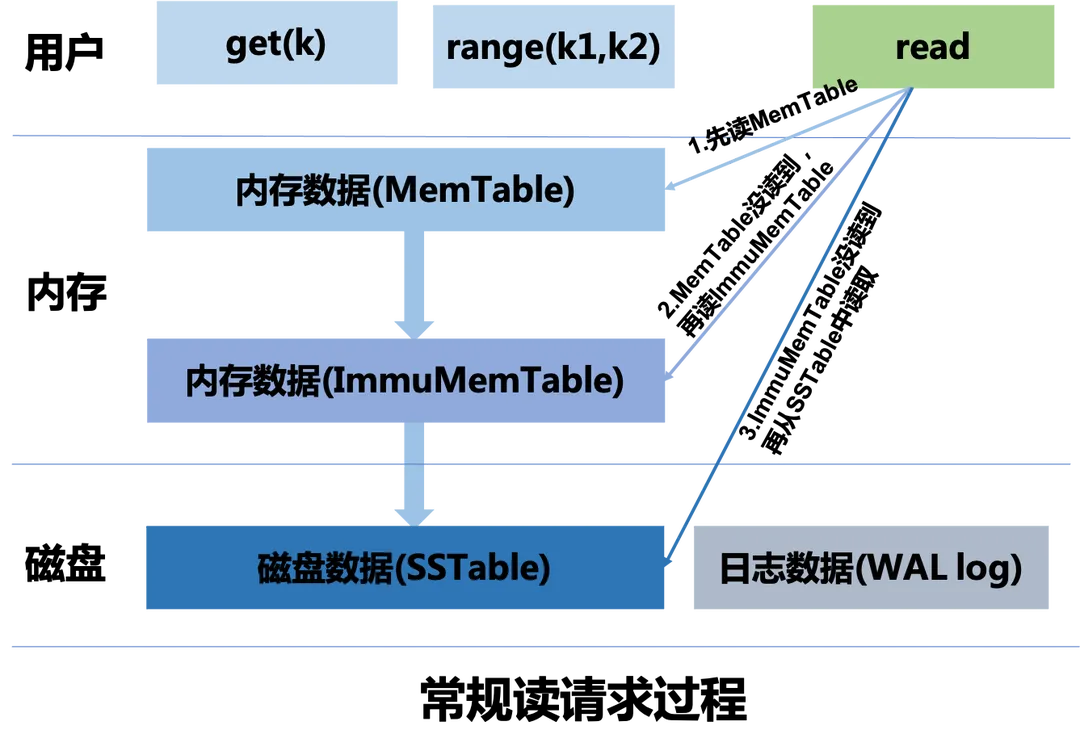
LSM 读取流程如上图:
- 首先从 MemTable 中尝试读取,如果读取到数据,则停止读取过程,立即返回
- 如果 MemTable 中数据未读到,则尝试从 ImmuMemTable 读取数据,如果读取到,则停止读取,返回给用户。
- 如果 ImmuMemTable 中数据未读到,则尝试从 SSTables 中读取数据(此处省去繁琐的具体SSTable中读取数据的逻辑,因为涉及到数据时按照大小分级组织还是按照分层关系组织),最后将读取的数据返回给用户。
在极端情况下,如果我们要搜索的数据根本就不存在。那这种情况下,我们需要读取完所有的数据才能返回给上层用户,搜索的数据不存在。
当数据量较大时,这种查找过程效率极低。往往在工程上实现时,会采用布隆过滤器来加速读取,查找每个 SSTable 时,首先会根据布隆过滤器来拦截一次,如果布隆过滤器检测当前的查找的数据不存在,那么查找的数据就一定不存在当前的SSTable中,加快读取效率。不过布隆过滤器存在误判情况,所以在实际使用时,需要合理的设置布隆过滤器的几个关键参数。
合并机制
LSM树引入了合并(Compaction)机制,可以降低空间放大和读放大,但代价是更高的写放大(Write Amplification),即实际写入操作数量大于真正的写入操作数量。
在合并操作中,每个被合并的 SSTable 中的数据都需要被读取出来,然后写入到新的 SSTable 中。因此,一个数据项可能会被多次写入到硬盘中.
写放大会增加硬盘I/O,尤其是在业务高峰期,从而降低系统的性能。因此LSM树提供了不同合并策略在空间、读和写放大之间进行权衡,这种策略主要包括
- 分层合并(Tiered Compaction) : 按照key的范围分裂成多个小文件SSTable,旧数据被移动到单独的层级
- 大小层分级合并(Leveled Compaction) : 较新的和较小的SSTable文件被连续合并到较旧的、较大的文件SSTable中
总结
从上面的读写流程, lsm 的核心设计思想(要解决的问题)如下:
- 首先 LSM 是为了解决大量写的场景, 写操作无非是add、update、delete, 要想加快写的速度, 选择了追加写(假设数据已经组织成了: [op, key, value] 形式)
- 对于同一个 key 来说, 我们只关心最终的 value, 中间的 op 过程是无效的, 这种情况被称为 空间放大, 解决办法是进行合并压缩数据
- 合并压缩的过程中又引入了新的问题: (1)合并的过程中阻塞了写入和读取 (2)每次合并需要读取整个文件,比较耗时
- 针对合并过程阻塞读写, 解决方案是将原先单个文件存储转为采用多个小文件 分段存储数据,这样的话每次当一个文件写入的数据达到一定条件后就关闭,不再修改,然后重新打开一个新文件进行写入数据不就好了。然后合并的时候对前面关闭的一些文件进行定期压缩。这样我们的第一个问题就得到解决了。压缩过程不会阻塞读写过程. 具体的压缩逻辑大致如下:
- 依次按照文件关闭先后顺序倒序读取多个文件内容到内存
- 内存中保留最新的数据(越后写入的数据越新)即可
- 最后合并的数据写入到新文件中
- 针对压缩比较慢的问题,利用 多路归并 的思想, 保证每个文件的写入是有序的。 这里可以选择一定的数据结构来在内存中排序如: AVL,红黑树,跳表等
- 数据在内存中如果断电了, 数据就丢失了, 为了保证数据的持久性, 又引入了 WAL, 所有操作先写 redo log, 挂掉重启从 redo log 中恢复
- 合并压缩的策略选择
可以看到每个问题 lsm tree 都抽象了一些模块来解决:
- 内存数据(MemTable): 内存数据主要缓存我们写入进来的数据,因为是内存数据所以称为MemTable。一般选择跳表或者红黑树等有序数据结构实现。
- 磁盘数据文件(SSTable):磁盘数据文件,保存我们所有的用户数据,数据有序存储,所以又称为SSTable(Sorted String Table) 。
- 磁盘日志文件(WAL log):预写日志文件,主要用来程序异常退出重启时恢复数据,保证数据可靠性,WAL全程write ahead log。