从ES底层原理来看查询优化
ES 底层设计概览
ES 底层(或者说内核)是基于 Lucene,本文从 ES 查询流程以及 Lucene 底层的一些存储结构设计设计, 来分析 ES 的一些查询优化方向
ES 查询模型
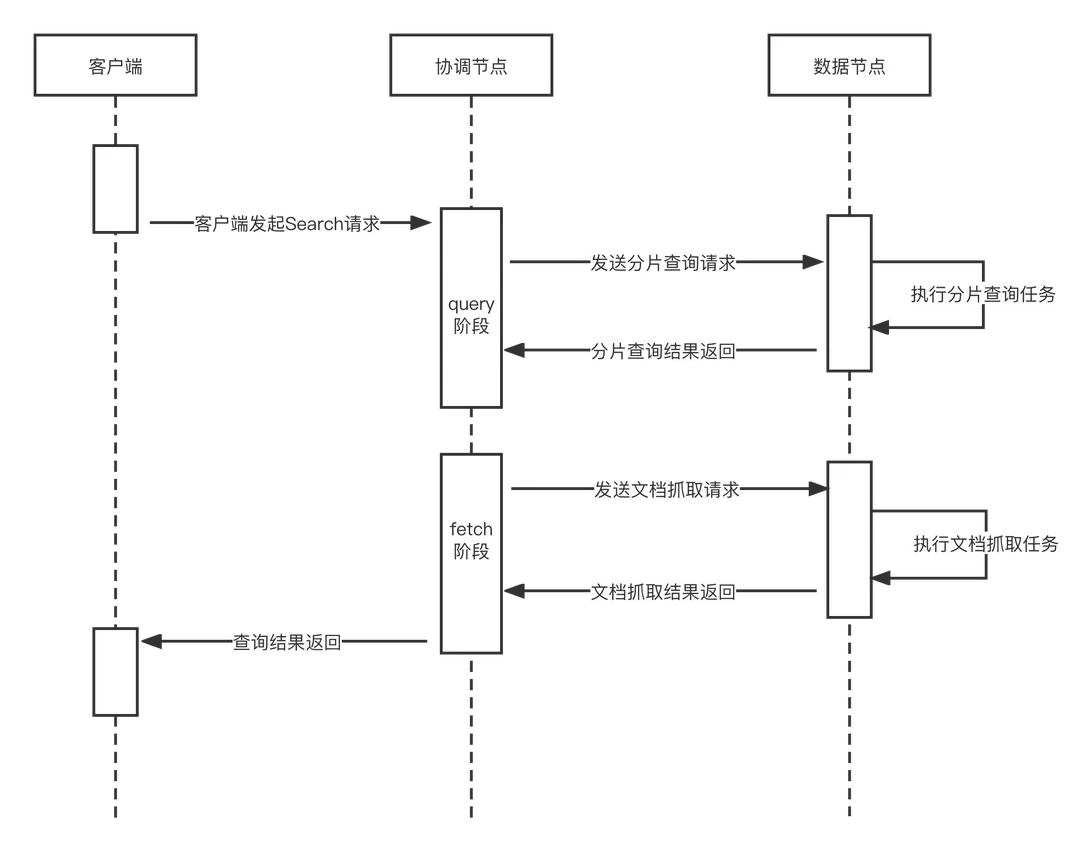
上图是 ES 的完整查询流程, ES 的任意节点可作为写入请求的协调节点(Coordinating Node),接收用户请求。协调节点将请求转发至对应一个或多个数据分片的主或者从分片进行查询,各个分片查询结果最后在协调节点汇聚,返回最终结果给客户端。 从查询流程可以看出 ES 的查询主要有2个阶段: Query 和 Fetch
- Query 阶段:协调节点将查询拆分成多个分片任务,发送到数据分片上通过调用 Lucene 执行查倒排索引,查询满足条件的文档 id 集合
- Fetch 阶段:归并生成最终的检索、聚合结果
当然如果 ES 只有一个分片, 那么整个流程将合并成 QueryAndFetch 一个阶段。
Lucene 索引设计
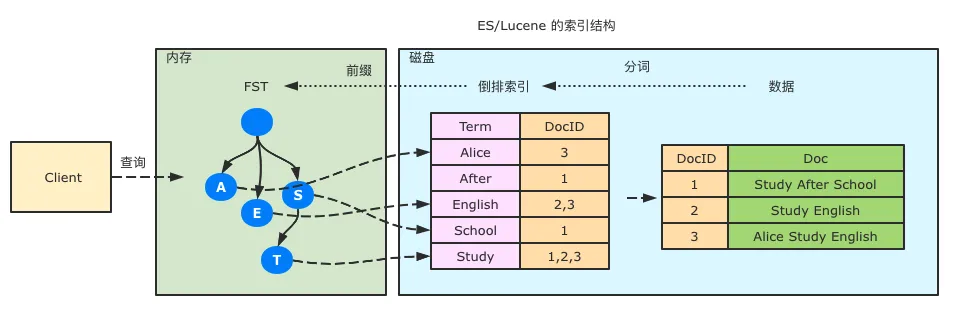
ES 底层是 Lucene, 说到索引设计, 大部分同学都知道 ES 是基于倒排索引来进行文档检索, 即一个分词(term)对应一个 docsList。
Lucene 的设计中, 倒排索引并非只是简单的一个 term-> docsList 的结构, 主要是采取了这几种数据结构:
倒排索引:保存了每个 term 对应的 docId 的列表,采用 skipList 的结构保存,用于快速定位到 term 所在位置
FST(Finite State Transducer):可以认为是前缀树的变种,用于保存 term 字典的二级索引,用于加速查询,可以在 FST 上实现单 Term、Term 范围、Term 前缀和通配符查询等。内部结构如下
BKD-Tree:BKD-Tree是一种保存多维空间点的数据结构,主要用于数值类型(包括空间点)的快速查找。在 ES 6.0 后引入, 取代了之前的 geohash 和 quatree
ES 的字段存储
除了索引外,ES 同时提供了行存(stored)、列存(doc_value)来进行业务字段的存储
Stored Field(行存储模式)
stored 是 ES 的行存储模式, 类似 innodb 的存储, 用于字段值的展示,特点如下:
- ES内置元数据字段(_index,_id,_score等等)默认开启store。
- 所有业务字段默认关闭store,但业务字段的store 都会被存到 _source。
- 默认通过 index.codec 压缩算法进行压缩。查询时需要解压
存储结构如下: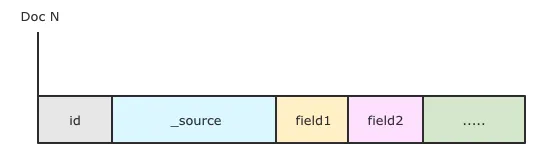
需要注意的是从上图可以看出 _source 是 stored field 的第一个字段, 会优先读取
doc_value Fields(列存储模式)
doc_value 是 ES 的列存储模式, 类似大数据的存储,用于聚合排序等分析场景, 特点如下:
- 不同文档的相同字段的值一起连续存储在内存中,默认不通过压缩算法压缩。可以直接访问某个文档的某个字段。调用方式:
"docvalue_fields": ["tag1"] - 数据被编码后,精度跟格式可能会发生变化。
- 非 text 类型默认开启 doc_value。text 字段无法直接开启 doc_value。
存储结构如下: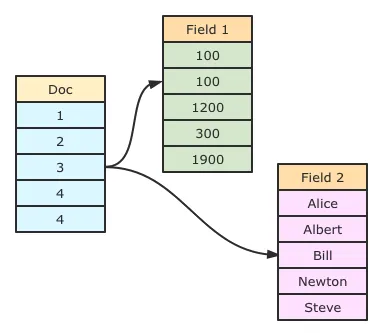
ES 优化策略
了解了 ES/Lucene 索引的一些底层设计, 那来看看一些优化方法论
分片数,副本数,索引规模的合理评估
在 ES 6.6 或以上的版本, 官方提供了索引生命周期管理(ILM index-lifecycle-manager)功能, 可以通过 kibana 或 API 来配置索引生命周期。实现索引数据的自动滚动跟过期,并结合冷热分离架构进行数据的降冷跟删除。
为了让分片查询性能发挥到最优,需要对规模进行限制,通常有以下使用原则:
- 集群总分片数建议控制在 5w 以内,单个索引的规模控制在 1TB 以内,单个分片大小控制在30 ~ 50GB ,docs 数控制在10亿内,如果超过建议滚动;
- 分片的数量通常建议小于或等于 ES 的数据节点数量,最大不超过总节点数的 2倍,通过增加分片数可以提升并发,如果负载用上不去,可以适当的增加分片;
- 每个业务查询都会拆分成多个分片小请求,分片数越多,查询聚合耗时越高,所以分片数并不是越多越好,在搜索场景合理控制分片数也可以提升性能。
Mapping 设计
ES 的 Mapping 类似于传统关系型数据库的表结构定义。
在ES 中,一旦一个字段被定义在了 mapping中,是无法被修改的(新增字段除外),所以一般我们需要修改索引的话,都会滚动或者重建索引,并采用 reindex 或 logstach 来迁移数据。 为了高效发挥 mapping 的性能并降低存储成本,介绍一些常见的使用技巧:
- ES 对于一份数据会建立索引, 根据不同的需要会行存、列存。为了节约存储成本, 对于某些不重要的字段可以通过指定(index: false , enabled: false ,doc_values: false)来关闭, 减少存储成本
- 段值太长会大幅增加 ES的序列化跟 Highlight 开销,且Lucene 限制单个 term 长度不能超过 65536,对于超长的值可以配置 ignore_above 忽略超长的数据,以避免性能的严重衰减。
- 字段可以设置子字段,比如对于 text 字段有 sort 和聚合查询需求的场景,可以添加一个keyword子字段以支持这两种功能
- 字段数量如果太多会降低ES 的性能,用户需要合理设计字段。同时为了避免字段爆炸,ES 有如下优化使用方式:
- 用户可以在某个父层级字段设置
enabled: false来防止其下面创建子字段 mapping ,但是能被行存查询出来。 - mapping 层级可以设置
dynamic=runtime,虽然加入新字段也会更新 mapping,但是新加入的字段不会被索引,也就是不会使得索引变大,不过虽然不被索引,但是新加入的字段依然可以被查询,只是查询的代价会更大(运行时构建)。所以这种类型一般不建议用在经常查询的条件字段上,而更适合用在一些不确定数据结构的日志类索引中。 - mapping 层级也可以设置
dynamic=strict(不允许新增一个不在 mapping中的字段,一旦新增的字段不在 mapping 定义中,则直接报错)或者dynamic=false(新字段不会被索引,不能作为查询条件,但是能被行存查询出来)
- 用户可以在某个父层级字段设置
Index Sorting
ES 在查询的时候会将请求下发到所有分片, 特殊情况下会造成很多分片空转(并不命中数据), 这里引申一个概念 查询裁剪, 通常有这几种:
- 索引裁剪:如果已经滚动产生了很多索引,这个时候每次通过别名查询全量索引时,一样会有大量空转查询,可以通过索引名特征或时间范围,指定具体的索引名进行查询(譬如日志场景, 如果使用索引别名查询, 就会命中所有已经滚动的索引, 造成大量索引空转)
- 分片裁剪(例如用户可以在查询URL 指定
preference=_shards:0或者routing来指定查某一个分片进行查询) - Segment裁剪: Segment 是分片内部的数据单元(需要修改 Lucene 内核来支持 segment 级别裁剪)
需要注意的是, 1,2两种都可以在用户程序级做到(通过查询 API), segment 级别的裁剪需要对 Lucene 内核进行修改适配
ES 在 6.0 以上版本提供 Index Sorting 功能
通过数据排序(类似 mysql 的二级索引能力, Elasticsearch会结合索引排序和查询条件对结果进行排序。如果查询条件与索引排序顺序一致,查询性能将得到显著提升),通过牺牲少量的写入性能,在写入时将文档归类放置存储,非常有利于查询裁剪
Merge 优化
Forcemerge 优化
ES 的写入模型采用的是类似 LSM-Tree 的存储结构。ES 实时写入的数据都在 lucene 内存 buffer 中,同时依赖写入 translog 保证数据的可靠性。当积攒到一定程度后,将他们批量写入一个新的 Segment。 这样,数据写入都是 Batch 和 Append(顺序追加),能达到很高的吞吐量。
但是这种方式,也会产生大量的小Segment,查询时会产生非常多的随机IO,导致查询效率低下。
ES后台会进行 segment merge(段合并) 操作,但是默认段合并非常缓慢。这是因为 merge 操作比较吃IO,为了避免跟写入争抢IO,所以默认 merge 得非常慢。所以我们可以通过强制的 forcemerge (使用 _forcemerge API)来大幅降低Segment 数量,减少函数空转跟随机IO,极限压测通常大约能提升20%~30%的查询性能。
特别是业务刚迁移到新集群的热数据,一开始写入时产生的segment较多,导致查询性能相对于老集群反而变弱,需要等待一段时间让ES做merge 后性能才会变好。这种情况下,如果能做强制一把 forcemerge 就最好
Force Merge 是非常占用系统资源的, 尽量避免在线上业务期间使用
减少Merge
上面也提到了 Merge 是非常吃IO的操作。
通常在搜索场景下,merge 可以很好的提升查询性能,但是在日志场景下,写多读少,merge 并非十分必要,甚至可以放到深夜低峰期去做也是可以的。所以通过限制白天 merge 的线程数跟size限制, 可以有效降低集群负载
减少 Merge 可以通过调整集群配置中索引刷新间隔
index.refresh_interval来实现, 不过会影响数据的实时性
缓存设计优化
在文章开头介绍过 ES 的查询流程, 整个查询流程可以分为汇总后, 可以分为四个阶段的 cache:
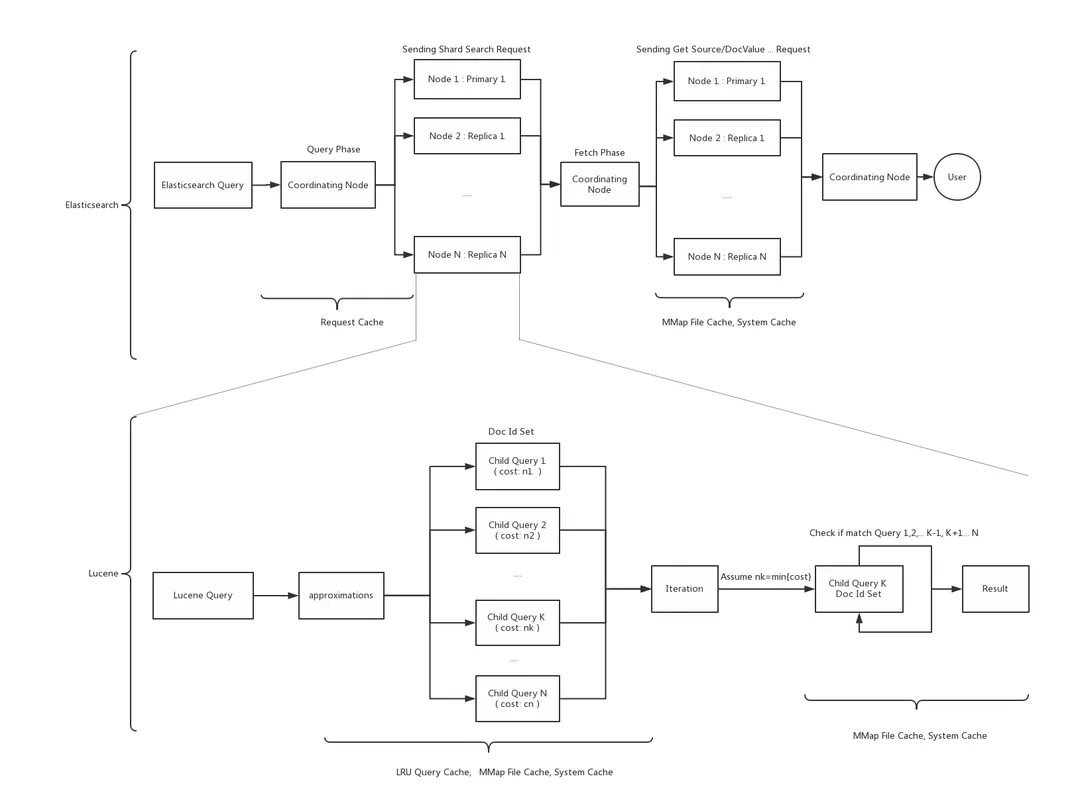
- 第一层缓存是Elasticsearch的RequestCache,缓存的是整个查询的Shard级别的查询结果,如果数据节点收到重复的查询语句的请求,那么这级缓存就能利用上。
- 第二层缓存是Lucene的LRUQueryCache,缓存的是单条子查询语句的查询结果,如果有类似的查询进来,部分子查询重复,那么LRUQueryCache便能够发挥作用。
- 第三层缓存是程序内存中的MMAP文件映射缓存,Lucene通过DirectByteBuffer将整个文件或者文件的一部分映射到堆外内存,由操作系统负责获取页面请求和写入文件,Lucene就只需要读取内存数据,这样可以实现非常快速的IO操作。
- 第四层缓存是文件系统缓存,是由系统控制的。
ES 可以在这些地方配置缓存使用:
- 系统缓存 (page cache/buffer cache) :由 Linux 控制,ES 使用系统页缓存可以减少磁盘的访问次数。如果用户的索引比用户的内存配置小,可以通过配置
"index.store.type": "mmapfs"让ES 尽可能将数据全部装入缓存。(ES 默认使用 NIOFS 读行存,所以默认读行存一定会读盘。) - 分片级请求缓存(Shard Request Cache):请求级别的查询缓存,主要用于缓存聚合结果跟 suggest 结果。
- 节点级查询缓存(Node Query Cache):Segment 级别的查询缓存,主要用于缓存某个字段的查询结果,并且由节点级别的LRU策略来控制。使用 Filter 可以告知 ES 优先对某些查询语句优先进行缓存。 需要注意的是,当索引过大时,构建Node Query Cache 可能会造成查询毛刺,并占用较多的内存,可以通过
indices.queries.cache.count调节,或者通过index.queries.cache.enabled关闭。
批量拉取
ES 批量拉取数据的场景下通常有以下几种方式:
from + size :非常不建议,ES 默认限制 from + size < 10000,在分布式系统中深度翻页排序的花费会随着分页的深度而成倍增长,如果数据特别大对CPU和内存的消耗会非常巨大甚至会导致OOM。
滚动翻页(Search Scroll): 使用 ES Scroll API 对某次查询的结果生成一个临时的结果快照跟游标
scroll_id,在此之后的增删改查等操作不会影响到这个快照的结果。后续的查询只需要根据这个游标去取数据,直到结果集中返回的 hits 字段为空,就表示遍历结束。需要注意的是,每一个结果快照保存了全部的查询结果 doc 列表,所以会占用大量的资源,同时存在游标过多或者保存时间过长,会非常消耗内存。当不需要 scroll 数据的时候,尽可能快的把 scroll_id 显式删除掉(Delete scroll_id)。 Search_Scroll 在深度翻页场景有如下缺点:- scroll api 会缓存查询结构, 翻页越深, 内存占用越多, ES 需要处理的数据越多, 导致性能下降
- scroll 是根据快照进行查询,翻页的过程中可能会丢失实时更新的数据
流式翻页(Search After)(7.10之前版本):这种方式是通过维护一个实时游标来避免 scroll 的缺点(不再生成游标快照, 并且不受深度翻页的性能影响),它可以用于实时请求和高并发场景。因为 Search After 读取的并不是不可变的快照,而是依赖于上一页最后一条数据,所以无法跳页请求,用于滚动请求,与Scroll类似,不同之处在于它是无状态的,不需要像Scroll那样在内存中维护一个庞大的对象,所以内存占用较低。需要注意使用这种方式的条件是需要至少指定一个唯一不重复字段来排序。 Search_After 的流程:
- 发送一个查询 dsl, 需要指定排序字段(指定 sort), 带上 size 参数指定页大小
- 请求成功得到响应, 拿到
_sort中当前响应的最后一个结果 - 下一次查询带上
search_after查询, 值为_sort返回的结果
相比 scroll api, search_after 会更加的高效和实时, 但是 search_after 参数使用上一页中的一组排序值来检索下一页的数据。(增加一个条件查询 排序值 > 上一页排序值 )使用 search_after 需要具有相同查询和排序值的多个搜索请求。 如果在这些请求之间发生刷新,结果的顺序可能会发生变化,从而导致跨页面的结果不一致。
- 流式翻页(Search After PIT)(7.10 以后版本): 在 es7.10 版本以后 search after 增加了通过
pit API(point in time,轻量化视图)参数来支持一个有状态的翻页查询,能够解决上述的实时性问题
整体流程如下:- 用户发送查询 dsl, 带上
point_in_time参数, 例如"point_in_time": {"keep_alive": "1m"}代表 pit 保持打开 1min - 请求成功会返回一个
x-elastic-id, 后续的请求中要使用这个值 - 下一次请求的
search_after中添加x-elastic-id来进行翻页
- 用户发送查询 dsl, 带上
总结:
- pit 的缓存复用率是比Search Scroll要高的:比如有100w 个Scroll 查询进来,内存中需要缓存100w个Scroll 查询结果。但是pit 缓存的shard 内存引用实际上很多查询之间是可以复用的,按理说内存消耗会更低。
- search scroll 是有状态的。Search After 原本是无状态的,但是pit 是有状态的,所以pit 解决了Search After 的无状态问题,同时也优化了Search Scroll的内存占用问题
参考资料
- 关于Lucene词典FST深入剖析
- [KM文章-腾讯云ES让你的查询性能飞起来]
- [KM文章-通过缓存提升ElasticSearch查询性能]
- 腾讯云ES:PB日志查询大提速,自治索引查询裁剪详解