k8s_service网络原理
k8s 中网络访问方式
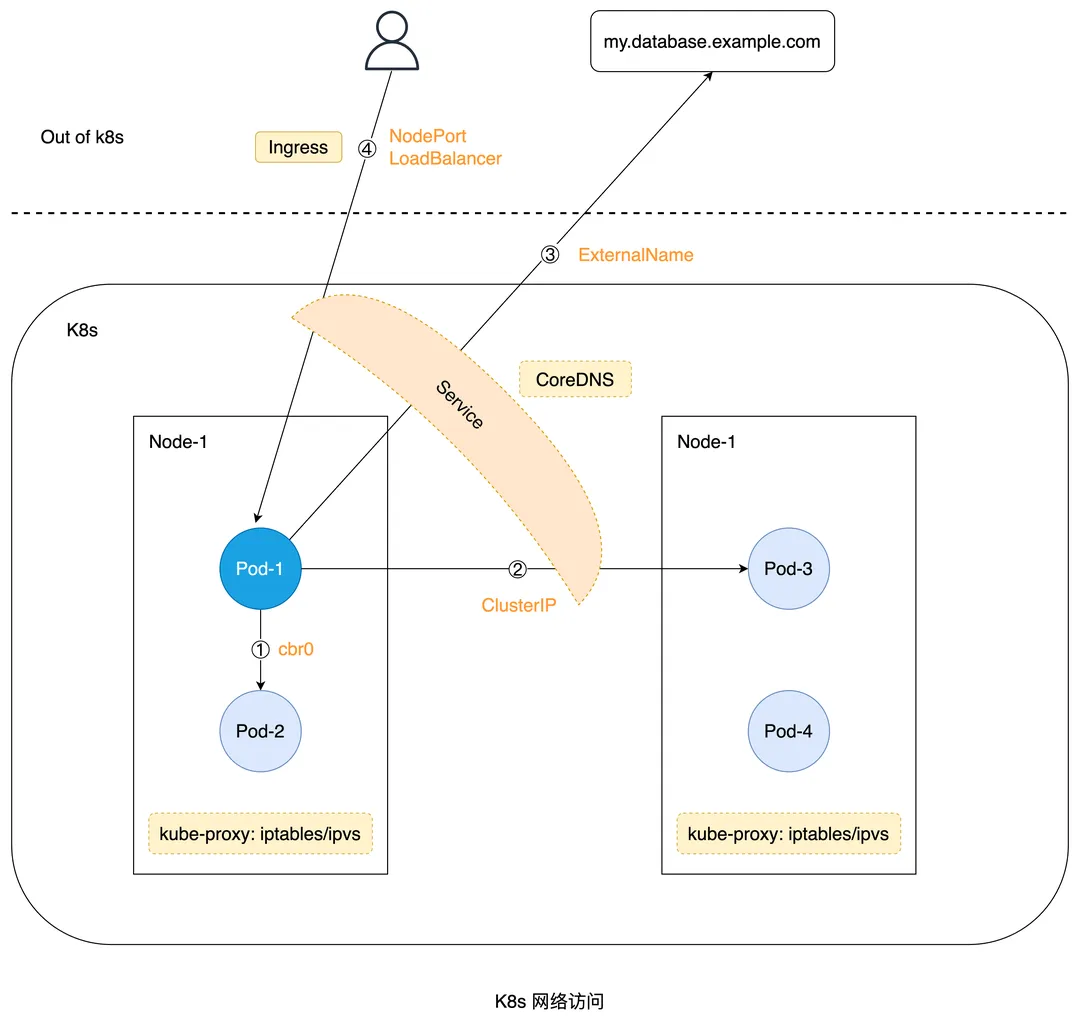
如上图, K8s 目前有四种网络访问方式:
- 同一个 Node 内 Pod 访问
- 跨 Node 间 Pod 访问
- Pod 访问集群外服务
- 集群外访问集群内 Pod
网络空间的隔离
network namespace 是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自的网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己就在独立的网络中。对于每个 network namespace 来说,它会有自己独立的网卡、路由表、arp表、iptables 等和网络相关的资源。相关的主要命令如下:
1 | |
不同网络空间的通信
为了实现不同 network namespace 之间的网络通信,linux提供了 veth pair,可以将 veth pair 当做一对虚拟网卡,这对虚拟网卡连通着不同的网命名络空间(Docker 与宿主机之间也是这种模式)
如下, 创建两个网络空间, 通过 veth pair 联通:
1 | |
多个网络空间的通信
不同 namespace之间,两两之间直接通过veth pair相连,这种方式的缺点就是:当namespace很多时,veth pair数量呈指数增长。
通过linux bridge,相当于用一个交换机中转两个 namespace 的流量。这种方式就可以将veth pair的数量控制在n,n为网络命名空间的数量, 如: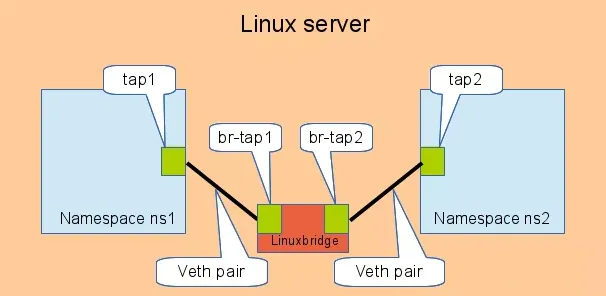
容器(Pod)通信
同 Node 上通信
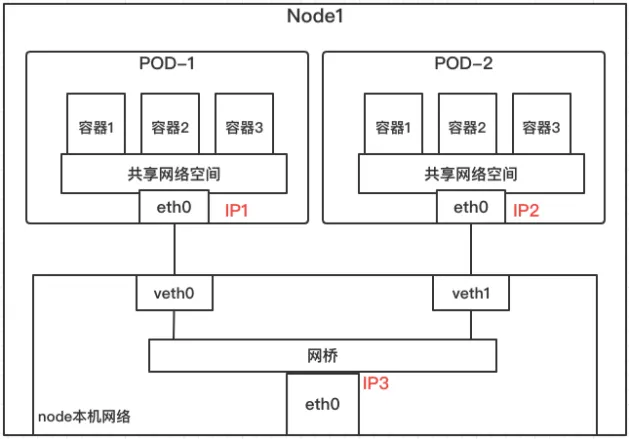
在同一个Node上: 虚拟网桥与各个Pod间建立veth pair。各个Pod的IP是由虚拟网桥分配的,这些Pod都连在同一个网桥上,在同一个网段内,它们可以进行IP寻址和互通。
整体流程如下:
- Node 会在
Docker/containerd启动后, 创建默认的网桥 cbr0(custom bridge), 以连接当前 Node 上管理的所有容器 - Pod 创建后,会在
Pod Sandbox初始化基础网络时,调用 CNI bridge 插件创建 veth-pair(两张虚拟网卡),一张默认命名 eth0 (如果 hostNetwork = false,则后续调用 CNI ipam 插件分配 IP)。另一张放在 Host 的Root Network Namespace内,然后连接到 cbr0。当 Pod 在同一个 Node 内通信访问的时候,直接通过 cbr0 即可完成网桥转发通信。
跨 Node 通信
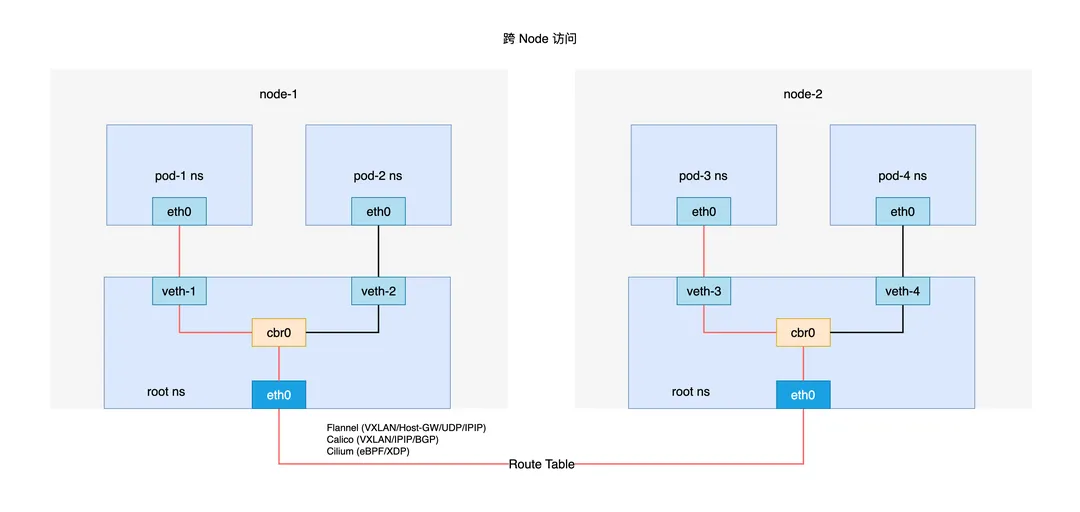
跨 Node 的 Pod 通信, 流程如下:
- 跨 Node 间访问,Pod 访问流量通过 veth-pair 打到 cbr0
- 流量通过经过 cbr0 到宿主机的 eth0
- 通过 Node 之间的路由表 Route Table 进行转发, 到达目的 Node2 eth0
- Node2 eth0 转到 cbr0 再通过 veth-pair 到 Pod
Service 网络类型
Service 共有四种网络类型, 用来应对内外的网络访问:
- ClusterIP(默认): k8s 集群可访问
- NodePort: k8s 上所有 Node 可访问
- LoadBalancer: k8s 外部访问的 vip
- ExternalName: k8s 内部访问外部服务
ClusterIP
ClusterIP 表示在 K8s 集群内部通过 service.spec.clusterIP 进行访问,之后经过 kube-proxy 负载均衡到目标 Pod
当没有指定 service.type 的时候, 默认的 service 类型就是 ClusterIP
NodePort
当业务需要从 K8s 集群外访问内部服务时,通过 NodePort 方式可以先将访问流量转发到对应的 Node IP,然后再通过 service.spec.ports[].nodePort 端口,通过 kube-proxy 负载均衡到目标 Pod:
1 | |
上述 yaml 中各个 port 的区别:
- nodePort:
NodePort/LoadBalancer类型的 Service 在 Node 节点上动态(默认)或指定创建的端口,负责将节点上的流量转发到容器 - port:Service 自身关联的端口,通过 Service 的
ClusterIP:port进行集群内的流量转发。 - targetPort:目标 Pod 暴露的端口,承载 Service 转发过来的流量;未指定时与 port 相同。
NodePort 本质上是靠 kube-proxy 监听集群每个节点上的静态端口(一般是 30000-32767), 然后将流量根据 service 的配置转发到对应 pod, 这种模式比较简单提供了集群外访问 pod 的能力
LoadBalancer
上面介绍的 NodePort 模式能够暴露集群外访问的能力, 不过有如下缺点:
- 无法高可用, 如果对外暴露的 Node IP 所在的 Node down 了就无法提供服务了
- 无法负载均衡,需要用户手动在 NodePort 之上配置负载均衡转发
- 端口限制: NodePort的端口范围是固定的(30000-32767),可能不足以支持大量的服务
LoadBalancer 模式可以解决以上问题, 创建了 LoadBalancer 的 Service 后, 会调用云厂商的能力创建一个 LB 与之关联。 相当于复用了云厂商 LB 的负载均衡能力:
1 | |
ExternalName
当业务需要从 K8s 内部访问外部服务的时候,可以通过 ExternalName 的方式实现:
1 | |
service.spec.externalName 字段值会被解析为 DNS 对应的 CNAME 记录,之后就可以访问到外部对应的服务了
DNS 机制: CoreDNS
在 K8s 中访问 Service 一般通过域名方式如 svc.namespace.svc.cluster.local,从域名结构可以看出对应 Service 的 namespace + name,通过这样的域名方式可以大大简化集群内部 Service-Pod 之间的访问配置,并且域名屏蔽了后端 Pod IP 的变更。
该能力最早是由 kube-dns 组件实现的, 在 1.12 版本以后就由 coreDNS 方案来实现
CoreDNS 通过以 Pod 独立部署在集群中, 当 Kubernetes 集群中的应用程序或服务需要解析另一个服务或资源的名称时,它们会发送 DNS 查询请求到 CoreDNS, CoreDNS使用配置文件(如Corefile)来定义DNS解析规则和插件。这些规则指定了如何处理不同类型的DNS查询请求。
CoreDNS与Kubernetes API服务器集成,可以从Kubernetes API获取服务、端点和其他资源的信息
CoreDNS 机制原理:
- 服务发现:CoreDNS通过监听 Kubernetes API服务器的变化,实时获取集群中服务的信息。当服务发生变化时,CoreDNS会自动更新其DNS记录
- DNS记录生成:CoreDNS根据 Kubernetes 服务的元数据生成DNS记录。例如,对于每个 Kubernetes 服务,CoreDNS会生成一个A记录(IPv4)和一个AAAA记录(IPv6),指向服务的IP地址。此外,还会生成SRV记录,表示服务的端口号
- DNS查询处理:当接收到DNS查询请求时,CoreDNS会根据查询类型和域名查找相应的DNS记录。对于服务名称查询,CoreDNS会返回与该服务关联的Pod的IP地址
- 插件机制:CoreDNS支持插件机制,允许开发者扩展其功能。例如,可以使用插件实现日志记录、缓存、负载均衡等功能
kube-proxy
我们从上面的章节可以看出 Service 最终负载均衡到后端的目标 Pods 是靠 kube-proxy 实现的。
随着 K8s 版本不断演进,kube-proxy 分别支持了多种工作模式:
- userspace
- iptables(当前的默认模式)
- ipvs
userspace
在 K8s v1.2 版本之前的默认模式,这种模式下 Service 的请求会先从用户空间进入内核 iptables,然后再回到用户空间,由 kube-proxy 完成后端 Endpoints 的选择和代理工作。
这样流量从用户空间进出内核带来的性能损耗是不可接受的,因此从 v1.2 版本之后默认改为 iptables 模式
iptables
iptables 是 K8s 中当前默认的 kube-proxy 模式,核心逻辑是使用 iptables 中 PREROUTING 链 nat 表,实现 Service => Endpoints (Pod IP) 的负载均衡:
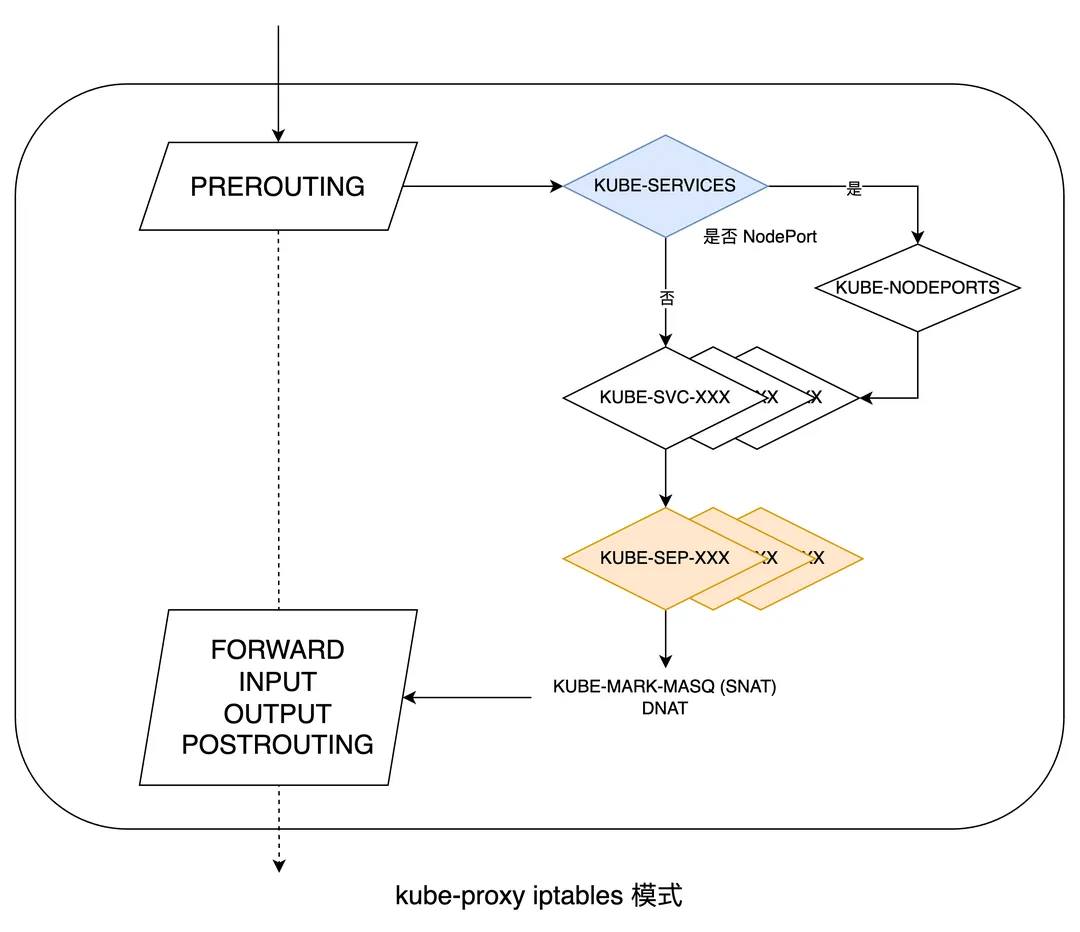
具体来说,访问 Service 的流量到达 Node 后,首先在 iptables PREROUTING 链中 KUBE-SERVICES 子链进行过滤:
1 | |
接着,KUBE-SERVICES 链中会将所有 Service 建立对应的 KUBE-SVC-XXX 子链规则(KUBE-SVC-XXX 或其他 KUBE-XXX 相关的 Chain,后面的 XXX 是统一将部分字段(如 servicePortName + protocol)经过 Sum256 + encode 后取其前 16 位得到。
),若 Service 类型是 NodePort,则命中最下面的 KUBE-NODEPORTS 子链:
1 | |
接着,某个 Service 对应的 KUBE-SVC-XXX 子链的目的地 (target) 将指向 KUBE-SEP-XXX,表示 Service 对应的 Endpoints,一条 KUBE-SEP-XXX 子链代表一条后端 Endpoint IP。
1 | |
可以看到上面的包含一条 KUBE-SEP-xxx 子链, 代表这个 Service 后面就一个 Pod
继续查看某个 KUBE-SEP-XXX 子链的规则如下:
1 | |
命中某个 KUBE-SEP-XXX 子链后,可以看到其目的地有两个:
- KUBE-MARK-MASQ:流量从目标 Pod 出去的 SNAT 转换,表示将 Pod IP -> Node IP。
- DNAT:流量进入目标 Pod 的 DNAT 转换,表示将 Node IP -> Pod IP
ipvs
ipvs (IP Virtual Server) 是 LVS (Linux Virtual Server) 内核模块的一个子模块,建立于 Netfilter 之上的高效四层负载均衡器,支持 TCP 和 UDP 协议,在这种模式下,kube-proxy 将规则插入到 ipvs 而非 iptables。
ipvs 具有优化的查找算法(哈希),复杂度为 O(1)。这意味着无论插入多少规则,它几乎都提供一致的性能。ipvs 支持多种负载均衡策略,如轮询 (rr)、加权轮询 (wrr)、最少连接 (lc)、源地址哈希 (sh)、目的地址哈希 (dh)等,K8s 中默认使用了 rr 策略。
尽管它有优势,但是 ipvs 可能不在所有 Linux 系统中都存在。与几乎每个 Linux 操作系统都有的 iptables 相比,ipvs 可能不是所有 Linux 系统的核心功能。如果集群中 Service 数量不太多,iptables 应该就够用了。