限流算法
固定窗口
实现思路:
- 在一个时间周期内每来一次请求就将计数器+1
- 如果计数器超过了限制数量, 则拒绝服务
- 时间达到下一个时间窗口, 计数器重置
优点:
- 实现简单:固定窗口算法的实现相对简单,易于理解和部署
- 使用稳定,有较好的适用性: 可以根据需要调整时间窗口和限流速率,以适应不同的系统负载要求
缺点:
- 请求分布不均匀:固定窗口算法中,窗口内的请求分布可能不均匀,导致某些窗口内的请求数量超过阈值,而其他窗口内的请求较少。
- 无法应对突发流量:固定窗口限流不能很好地处理突发流量。如果在窗口的开始时刻有大量请求涌入,系统可能会超过预期的负载。
- 临界问题:在窗口切换的瞬间,可能会有一段时间窗口内的请求量达到限流阈值,而新窗口刚开始时又允许大量请求进入,这可能导致系统负载波动。
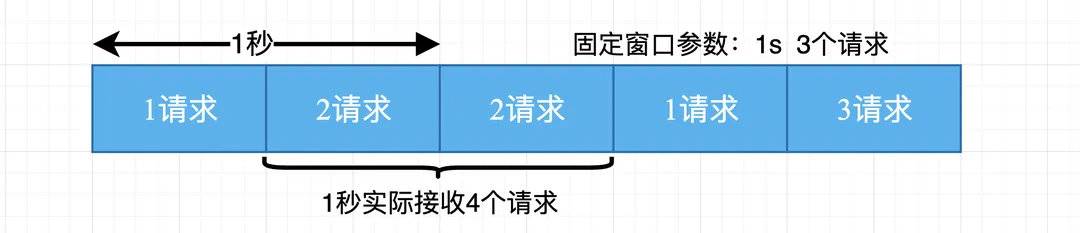
总结: 固定窗口算法适用于对请求速率有明确要求且流量相对稳定的场景,但对于突发流量和请求分布不均匀的情况,可能需要考虑其他更灵活的限流算法。
滑动窗口
- 将时间周期设置为滑动窗口大小
- 当有新的请求来临时将窗口滑动到改请求来临的时刻
- 判断窗口内的请求数是否超过了限制, 超过则拒绝服务, 否则请求通过
- 丢弃滑动窗口以外的请求
这里贴一个 go 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| type SlidingWindowLimiter struct {
windowSize time.Duration
maxRequests int
requests []time.Time
requestsLock sync.Mutex
}
func NewSlidingWindowLimiter(windowSize time.Duration, maxRequests int) *SlidingWindowLimiter {
return &SlidingWindowLimiter{
windowSize: windowSize,
maxRequests: maxRequests,
requests: make([]time.Time, 0),
}
}
func (limiter *SlidingWindowLimiter) AllowRequest() bool {
limiter.requestsLock.Lock()
defer limiter.requestsLock.Unlock()
currentTime := time.Now()
for len(limiter.requests) > 0 && currentTime.Sub(limiter.requests[0]) > limiter.windowSize {
limiter.requests = limiter.requests[1:]
}
if len(limiter.requests) >= limiter.maxRequests {
return false
}
limiter.requests = append(limiter.requests, currentTime)
return true
}
|
优点:
- 灵活性:滑动窗口算法可以根据实际情况动态调整窗口的大小,以适应流量的变化。这种灵活性使得算法能够更好地应对突发流量和请求分布不均匀的情况。
- 实时性:由于滑动窗口算法在每个时间窗口结束时都会进行窗口滑动,它能够更及时地响应流量的变化,提供更实时的限流效果。
- 精度:相比于固定窗口算法,滑动窗口算法的颗粒度更小,可以提供更精确的限流控制。
缺点:
- 内存消耗:滑动窗口算法需要维护一个窗口内的请求时间列表,随着时间的推移,列表的长度会增长。这可能会导致较大的内存消耗,特别是在窗口大小较大或请求频率较高的情况下。
- 算法复杂性:相比于简单的固定窗口算法,滑动窗口算法的实现较为复杂。它需要处理窗口滑动、请求计数和过期请求的移除等逻辑,可能需要更多的代码和计算开销。
总结: 滑动窗口算法实际上是颗粒度更小的固定窗口算法,它可以在一定程度上提高限流的精度和实时性,并不能从根本上解决请求分布不均匀的问题。算法受限于窗口的大小和时间间隔,特别是在极端情况下,如突发流量过大或请求分布极不均匀的情况下,仍然可能导致限流不准确, 如下图:
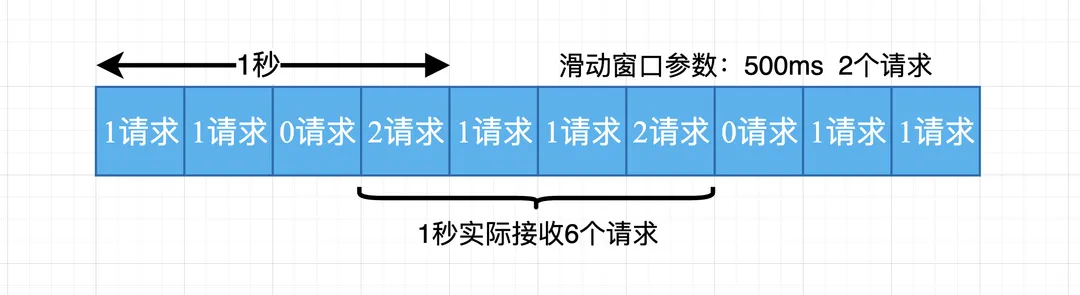
漏桶限流
滑动窗口在窗口大小和时间间隔不够精细的情况下, 仍然无法准确的应对突发流量, 漏桶可以视为滑动窗口的一个改进:
维护一个固定容量的漏桶,请求以不定的速率流入漏桶,而漏桶以固定的速率流出。如果请求到达时,漏桶已满,则会触发拒绝策略
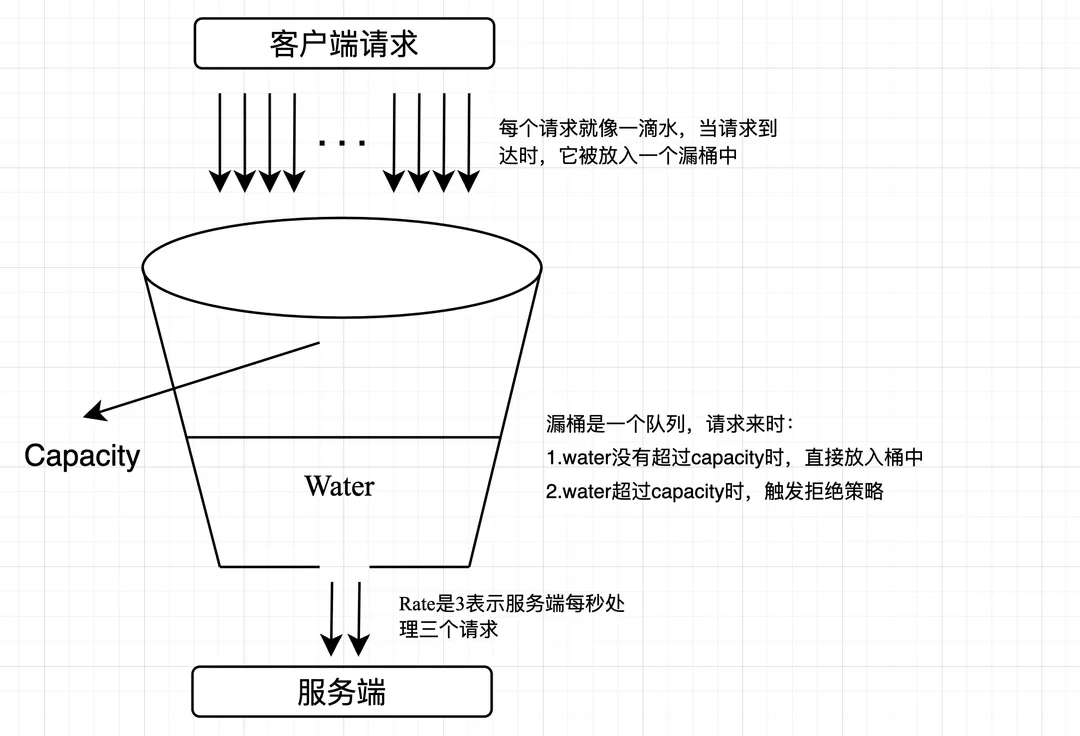
- 漏桶容量:确定一个固定的漏桶容量,表示漏桶可以存储的最大请求数。
- 漏桶速率:确定一个固定的漏桶速率,表示漏桶每秒可以处理的请求数。
- 请求处理:当请求到达时,生产者将请求放入漏桶中。
- 漏桶流出:漏桶以固定的速率从漏桶中消费请求,并处理这些请求。如果漏桶中有请求,则处理一个请求;如果漏桶为空,则不处理请求。
- 请求丢弃或延迟:如果漏桶已满,即漏桶中的请求数达到了容量上限,新到达的请求将被丢弃或延迟处理。
go 实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| type LeakyBucket struct {
rate float64
capacity int
water int
lastLeakMs int64
}
func NewLeakyBucket(rate float64, capacity int) *LeakyBucket {
return &LeakyBucket{
rate: rate,
capacity: capacity,
water: 0,
lastLeakMs: time.Now().Unix(),
}
}
func (lb *LeakyBucket) Allow() bool {
now := time.Now().Unix()
elapsed := now - lb.lastLeakMs
leakAmount := int(float64(elapsed) / 1000 * lb.rate)
if leakAmount > 0 {
if leakAmount > lb.water {
lb.water = 0
} else {
lb.water -= leakAmount
}
}
if lb.water > lb.capacity {
lb.water--
return false
}
lb.water++
lb.lastLeakMs = now
return true
}
|
优点:
- 平滑流量:漏桶算法可以平滑突发流量,使得输出流量变得更加平稳,避免了流量的突然增大对系统的冲击。
- 简单易实现:漏桶算法的原理简单,实现起来也相对容易。
- 有效防止过载:通过控制流出的流量,漏桶算法可以有效地防止系统过载。
缺点:
- 对突发流量的处理不够灵活:虽然漏桶算法能平滑流量,但在面对突发流量时,由于桶的容量有限,可能会导致部分请求被丢弃。
- 无法动态调整流量:漏桶算法的流出速率是固定的,无法根据系统的实际情况动态调整。
- 延迟问题:由于漏桶算法以恒定速率处理请求,当请求到达速度超过桶的处理能力时,请求会在桶中等待,从而导致一定的延迟。
总结: 漏桶算法控制流量流速绝对均匀, 适合流量比较平滑的场景(如数据库), 分布式的实现难度较滑动窗口来说复杂一些
令牌桶限流
令牌桶算法基本思路: 令牌以固定的速率产生,并放入桶中。每个令牌代表一个请求的许可。当请求到达时,需要从令牌桶中获取一个令牌才能通过。如果令牌桶中没有足够的令牌,则请求被限制或丢弃。 令牌桶算法的实现步骤如下:
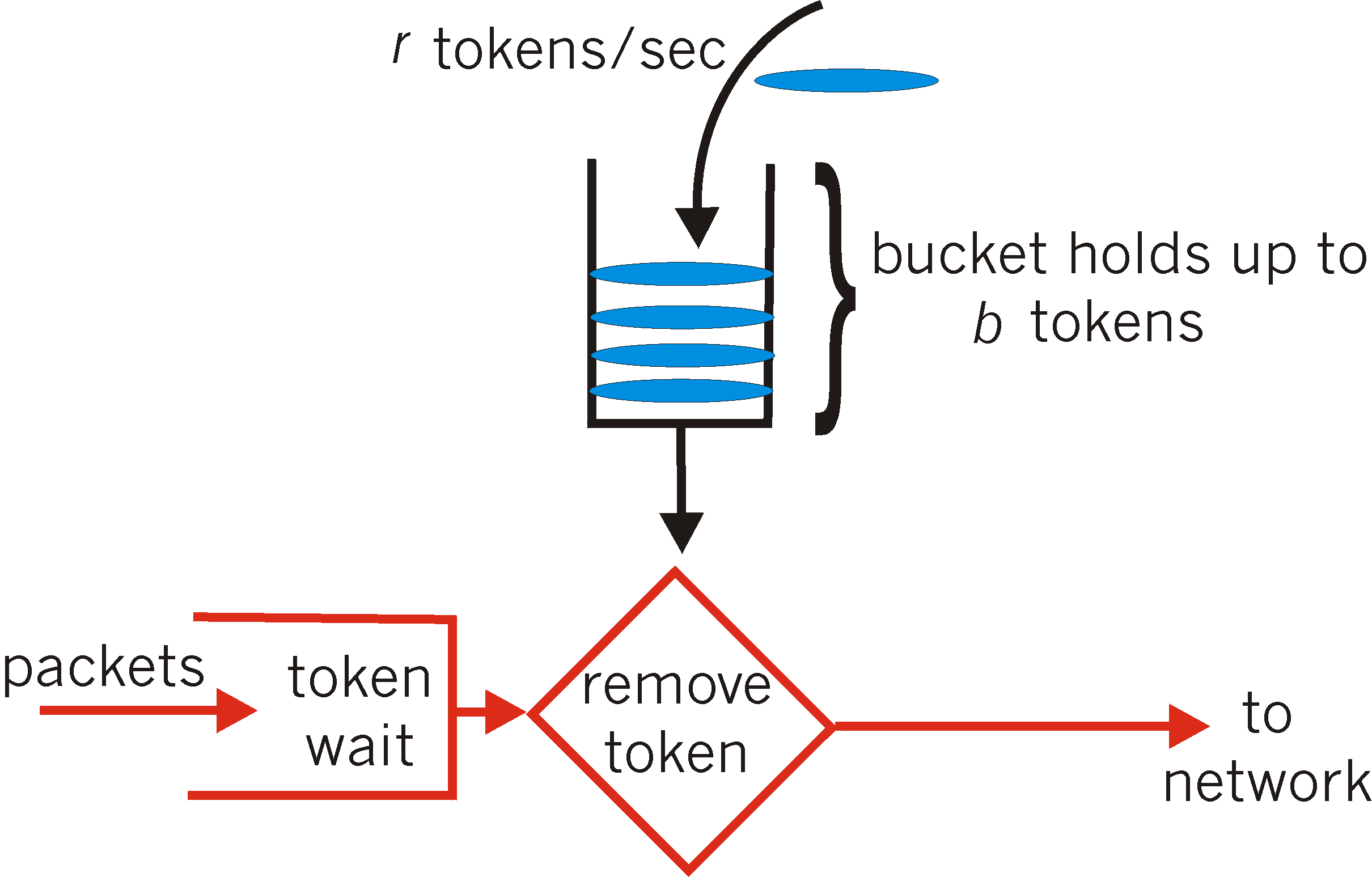
- 初始化一个令牌桶,包括桶的容量和令牌产生的速率。
- 持续以固定速率产生令牌,并放入令牌桶中,直到桶满为止。\
- 当请求到达时,尝试从令牌桶中获取一个令牌。
- 如果令牌桶中有足够的令牌,则请求通过,并从令牌桶中移除一个令牌。
- 如果令牌桶中没有足够的令牌,则请求被限制或丢弃。
go 代码简单实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
type TokenBucket struct {
rate float64
capacity float64
tokens float64
lastUpdate time.Time
mu sync.Mutex
}
func NewTokenBucket(rate float64, capacity float64) *TokenBucket {
return &TokenBucket{
rate: rate,
capacity: capacity,
tokens: capacity,
lastUpdate: time.Now(),
}
}
func (tb *TokenBucket) Allow() bool {
tb.mu.Lock()
defer tb.mu.Unlock()
now := time.Now()
elapsed := now.Sub(tb.lastUpdate).Seconds()
tokensToAdd := elapsed * tb.rate
tb.tokens += tokensToAdd
if tb.tokens > tb.capacity {
tb.tokens = tb.capacity
}
if tb.tokens >= 1.0 {
tb.tokens--
tb.lastUpdate = now
return true
}
return false
}
func main() {
tokenBucket := NewTokenBucket(2.0, 3.0)
for i := 1; i <= 10; i++ {
now := time.Now().Format("15:04:05")
if tokenBucket.Allow() {
fmt.Printf(now+" 第 %d 个请求通过\n", i)
} else {
fmt.Printf(now+" 第 %d 个请求被限流\n", i)
}
time.Sleep(200 * time.Millisecond)
}
}
|
优点:
- 平滑流量:令牌桶算法可以平滑突发流量,使得突发流量在一段时间内均匀地分布,避免了流量的突然高峰对系统的冲击。
- 灵活性:令牌桶算法可以通过调整令牌生成速率和桶的大小来灵活地控制流量。
- 允许突发流量:由于令牌桶可以积累一定数量的令牌,因此在流量突然增大时,如果桶中有足够的令牌,可以应对这种突发流量。
缺点:
- 实现复杂:相比于其他一些限流算法(如漏桶算法),令牌桶算法的实现稍微复杂一些,需要维护令牌的生成和消耗。
- 需要精确的时间控制:令牌桶算法需要根据时间来生成令牌,因此需要有精确的时间控制。如果系统的时间控制不精确,可能会影响限流的效果。
- 可能会有资源浪费:如果系统的流量持续低于令牌生成的速率,那么桶中的令牌可能会一直积累,造成资源的浪费。
四种限流算法整体对比
| 算法 | 优点 | 缺点 | 适合场景 |
|---|
| 固定窗口 | - 简单直观,易于实现
- 适用于稳定的流量控制
- 易于实现速率控制 | - 无法应对短时间内的突发流量
- 流量不均匀时可能导致突发流量 | 稳定的流量控制,不需要保证请求均匀分布的场景 |
| 滑动窗口 | - 平滑处理突发流量
- 颗粒度更小,可以提供更精确的限流控制 | - 实现相对复杂
- 需要维护滑动窗口的状态
- 存在较高的内存消耗 | 需要平滑处理突发流量的场景 |
| 漏桶算法 | - 平滑处理突发流量
- 可以固定输出速率,有效防止过载 | - 对突发流量的处理不够灵活
- 无法应对流量波动的情况 | - 需要固定输出速率的场景
- 避免流量的突然增大对系统的冲击的场景 |
| 令牌桶 | - 平滑处理突发流量
- 可以动态调整限流规则
- 能适应不同时间段的流量变化 | - 实现相对复杂 - 需要维护令牌桶的状态 | - 需要动态调整限流规则的场景
- 需要平滑处理突发流量的场景 |
- 固定窗口计数算法简单易实现,其缺陷是可能在中间的某一秒内通过的请求数是限流阈值的两倍,该算法仅适用于对限流准确度要求不高的应用场景。
- 滑动窗口计数算法解决了固定窗口计数算法的缺陷,但是该算法较难实现,因为要记录每次请求所以可能出现比较占用内存比较多的情况。
- 漏桶算法可以做到均匀平滑的限制请求,NGINX 热 limit_req 模块也是采用此种算法。因为匀速处理请求的缘故所以该算法应对限流阈值内的突发请求无法及时处理。
- 令牌桶算法解决了以上三个算法的所有缺陷,是一种相对比较完美的限流算法,也是限流场景中应用最为广泛的算法。使用 Redis + Lua 脚本的方式可以简单的实现
Guava RateLimiter
google 提供的 guava ratelimiter 是对令牌桶的一个非常经典的实现。
guava RateLimiter 作为抽象类有个子类 SmoothRateLimiter, 这是个抽象类并且又两个实现类:SmoothWarmingUp和SmoothBursty。
RateLimiter只有两个属性:
1
2
3
4
|
private final SleepingStopwatch stopwatch;
private volatile Object mutexDoNotUseDirectly;
|
SmoothRateLimiter
SmoothRateLimiter 作为抽象类继承于 RateLimiter。SmoothRateLimiter的属性如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
double storedPermits;
double maxPermits;
double stableIntervalMicros;
private long nextFreeTicketMicros = 0L;
|
nextFreeTicketMicros 是一个很关键的属性。每次获取 permits 的时候,先拿 storedPermits 的值,因为它是存货,如果够,storedPermits 减去相应的值就可以了,如果不够,那么还需要将 nextFreeTicketMicros 往前推,表示预占了接下来多少时间的量了。
那么下一个请求来的时候,如果还没到 nextFreeTicketMicros 这个时间点,需要 sleep 到这个点再返回,就要将这个值再往前推。
SmoothBursty
构造 SmoothBursty:
1
2
3
4
5
6
7
8
9
10
| public static RateLimiter create(double permitsPerSecond) {
return create(permitsPerSecond, SleepingStopwatch.createFromSystemTimer());
}
static RateLimiter create(double permitsPerSecond, SleepingStopwatch stopwatch) {
RateLimiter rateLimiter = new SmoothBursty(stopwatch, 1.0 );
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}
|
setRate
继续看 setRate 分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public final void setRate(double permitsPerSecond) {
checkArgument(
permitsPerSecond > 0.0 && !Double.isNaN(permitsPerSecond), "rate must be positive");
synchronized (mutex()) {
doSetRate(permitsPerSecond, stopwatch.readMicros());
}
}
final void doSetRate(double permitsPerSecond, long nowMicros) {
resync(nowMicros);
double stableIntervalMicros = SECONDS.toMicros(1L) / permitsPerSecond;
this.stableIntervalMicros = stableIntervalMicros;
doSetRate(permitsPerSecond, stableIntervalMicros);
}
|
resync 用来更新 storedPermits 和 nextFreeTicketMicros, 避免长时间不调用 acquire 导致不准确:
1
2
3
4
5
6
7
8
9
10
11
12
13
| void resync(long nowMicros) {
if (nowMicros > nextFreeTicketMicros) {
double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros();
storedPermits = min(maxPermits, storedPermits + newPermits);
nextFreeTicketMicros = nowMicros;
}
}
|
设置好了stableIntervalMicros、storedPermits和nextFreeTicketMicros, doSetRate 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = this.maxPermits;
maxPermits = maxBurstSeconds * permitsPerSecond;
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
storedPermits = maxPermits;
} else {
storedPermits =
(oldMaxPermits == 0.0)
? 0.0
: storedPermits * maxPermits / oldMaxPermits;
}
}
|
acquire
1
2
3
4
5
6
7
8
9
10
11
12
13
| public double acquire() {
return acquire(1);
}
public double acquire(int permits) {
long microsToWait = reserve(permits);
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return 1.0 * microsToWait / SECONDS.toMicros(1L);
}
|
reserve 预定 permits:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| final long reserve(int permits) {
checkPermits(permits);
synchronized (mutex()) {
return reserveAndGetWaitLength(permits, stopwatch.readMicros());
}
}
final long reserveAndGetWaitLength(int permits, long nowMicros) {
long momentAvailable = reserveEarliestAvailable(permits, nowMicros);
return max(momentAvailable - nowMicros, 0);
}
final long reserveEarliestAvailable(int requiredPermits, long nowMicros) {
resync(nowMicros);
long returnValue = nextFreeTicketMicros;
double storedPermitsToSpend = min(requiredPermits, this.storedPermits);
double freshPermits = requiredPermits - storedPermitsToSpend;
long waitMicros =
storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros);
this.nextFreeTicketMicros = LongMath.saturatedAdd(nextFreeTicketMicros, waitMicros);
this.storedPermits -= storedPermitsToSpend;
return returnValue;
}
|
从 reserve 的流程可看到,获取 permits 的时候,其实是获取了两部分,一部分来自于存量 storedPermits,存量不够的话,另一部分来自于预占未来的 freshPermits。
参考资料