使用redis作为延迟队列方案对比
背景
项目中经常需要做某个操作, 然后一定时间之后看这个操作的执行结果。 要么使用定时任务扫描, 要么使用延时队列(任务)来实现。
在主流的 MQ 中支持延时消息的有 RabbitMQ 和 RocketMQ, 如果没有使用这个两个 MQ, 譬如使用了 Kafka, 又想使用延时消息的功能可以使用 Redis来实现。
Redis 实现延时队列有三种方案:
- 基于
Zset(Sorted Set)来实现 - 基于 Redis 的 KEYSPACE NOTIFICATIONS 来监听 list 的 expire 事件
- 基于 Redis 的 Stream(需要 redis 5.0 及以上版本) 消费组来实现
基于 ZSet 实现延时队列
redis 可以基于 list 来实现队列, 通过 LPop 和 RPush 保证先入先出。
在延时队列场景可以使用 zset, 实现原理:
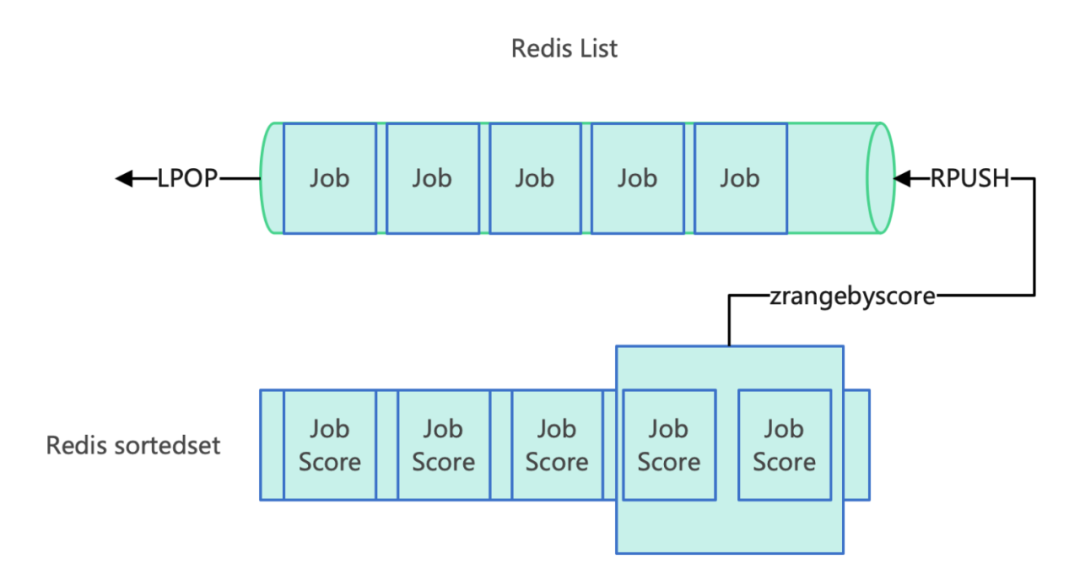
- score 存储到期时间的时间戳
- 定时轮询 zset, 使用到期时间作为 score, 使用
ZRANGEBYSCORE获取到期的消息, 将到期的消息迁移到 List 即可(或不要这一步, 直接消费)
消息迁移原子性
将到期消息的往 list 的迁移需要三个动作:
- 查询到期消息
- 从 sortedset 取出到期消息
- 将到期消息 push 到 list 队列中
这三个动作需要保证原子性(要么都成功,要么都失败), 可以使用 lua 脚本来实现。
备注: 虽然 redis 本身支持事务, 但是 redis 的事务机制不是那么合理, 当运行出错的时候会跳过出错的命令继续执行(只有语法错误才会失败), 并不能完全保证原子性, 所以大部分框架还是会选择用 lua 脚本
List 和 Zset 的性能
本章节摘取于其他文章的测试结果, 出处在参考资料
压测环境:
- 目标服务器为 8C16G
- redis 版本为 6.0
- 压测工具是
memtier_benchmark
Lpop和Rpush的时间复杂度是O(1):

- zset 的
zadd复杂度是 O(M*log(N)), N是有序集的基数,M为成功添加的新成员的数量
zadd benchmark 结果:
- zset 的
zrangebyscore复杂度是 O(log(N)+M), N 为有序集的基数, M 为被结果集的基数。
List + 监听 expire 事件
- 将消息放入 list 里面, 通过 lpop,rpush 操作任务的进出
- 开启
KEYSPACE NOTIFICATIONS监听过期事件:CONFIG SET notify-keyspace-events Ex - 消费者监听 list 对应 key 的 expire 事件后做出相应处理
KEYSPACE NOTIFICATIONS
Keyspace Notifications,可以用于监控 Redis 内的 Key 和 Value的变化,包括 Key 过期事件。像监听过期 Key 的功能就是通过 Keyspace Notifications 实现的。
基本原理是:Pub/Sub。客户端通过订阅 Pub/Sub 频道,来感知事件的发生。
开启 KEYSPACE NOTIFICATIONS:
1 | |
redis Pub/Sub 机制
Redis 可以通过 List 来做最简单的生产者消费者模式
- 早期阶段: 普通List, 生产者
Lpush发送, 消费者做一个死循环Rpop消费
这种最简单的模式, 有个很明显的问题。 当队列没有数据的时候, 消费者Rpop仍然会不停的拉消息, 会造成CPU的空转以及对Redis产生额外的压力
当然, Redis 也提供了阻塞的拉取:BRpop/BLpop, 这样可以避免CPU空转。
不过这仍然有几个问题:
- 不支持多消费者费: 消费者拉取消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费
- 消息丢失:消费者拉取到消息后,如果发生异常宕机,那这条消息就丢失了
Redis Pub/Sub 机制可以解决这个问题: 生产者通过 Publish 往 channel 发送消息, 消费者通过 Subscribe 订阅 channle, 一个 channel 可以被多个 Subscriber 订阅
不过仍然有这些缺陷:
- 不保证消息可靠性: 如果发布消息的时候,
Subscriber不在线, 那么这个消费就会丢失, 消息的可靠性得不到保证 - 不支持持久化: pub/sub 没有任何数据结构, 不会写入 AOF/RDB, 如果 Redis 宕机, 那么所有消息都会丢失
- 如果订阅者太多, 每次发送消息会对 Redis 造成较大的性能压力
该方案缺陷
- 开启 keyspace notifications 会带来额外的 CPU 开销。 如果事件通知非常频繁, redis Server 可能会积累大量的未通知事件, 占据大量内存
- 基于 pub/sub 模式消息传递是不可靠的, 如果客户端断开的过程中发送了消息, 此刻消息就丢失了(没有 MQ 的 ack 和 commit offset 机制)
- 过期事件的通知会有延迟, 因为 redis 发现 key 过期并非是 ttl 到 0, 而是 redis 发现过期才会通知(get 的时候或者线程扫描), 因此如果 key 非常多的时候, 可能会有分钟级的延迟
基于 Redis Stream 实现
Redis Stream 是干什么的?
Stream 是 Redis5.0 推出的一种数据结构, 主要用于当消息队列、日志分析等场景。
我们上面介绍的几种消息队列机制都有一些或多或少的问题:
- Redis List没有消息多播功能,没有ACK机制,无法重复消费等等。
- Redis Pub/Sub消息无法持久化,只管发送,如果出现网络断开、Redis 宕机等,消息就直接没了,自然也没有ACK机制。
- Redis Sorted Set不支持阻塞式获取消息、不允许重复消费、不支持分组。
Redis Steam 有如下机制:
- 提供了对于消费者和消费者组的阻塞、非阻塞的获取消息的功能。
- 提供了消息多播的功能,同一个消息可被分发给多个单消费者和消费者组;
- 提供了消息持久化的功能,可以让任何消费者访问任何时刻的历史消息;
- 提供了强大的消费者组的功能:
- 消费者组实现同组多个消费者并行但不重复消费消息的能力,提升消费能力。
- 消费者组能够记住最新消费的信息,保证消息连续消费;
- 消费者组能够记住消息转移次数,实现消费失败重试以及永久性故障的消息转移。
- 消费者组能够记住消息转移次数,借此可以实现死信消息的功能(需自己实现)。
- 消费者组提供了 PEL 未确认列表和 ACK 确认机制,保证消息被成功消费,不丢失;
Redis Stream 基本满足了消息队列的大部分要求
Redis Stream 数据结构
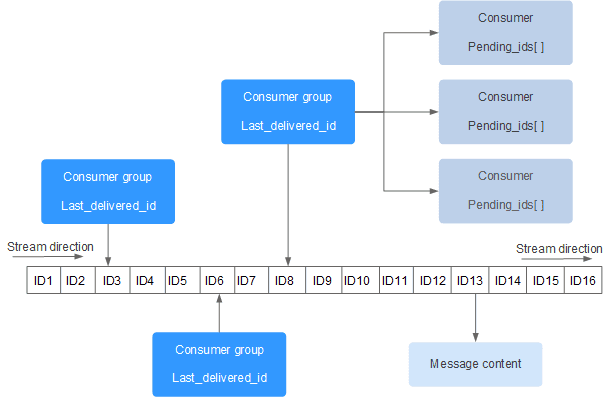
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在首次使用
XADD指令追加消息时自动创建。Consumer Group:参考了 Kafka 的概念, 消费者组,消费者组记录了 Stream 的状态,使用
XGROUP CREATE命令手动创建,在同一个 Stream 内消费者组名称唯一。一个消费组可以有多个消费者(Consumer)同时进行组内消费,所有消费者共享Stream内的所有信息,但同一条消息只会有一个消费者消费到,不同的消费者会消费 Stream 中不同的消息,这样就可以应用在分布式的场景中来保证消息消费的唯一性。last_delivered_id :游标,用来记录某个消费者组在 Stream 上的消费位置信息,每个消费组会有个游标,任意一个消费者读取了消息都会使游标
last_delivered_id往前移动。创建消费者组时需要指定从 Stream 的哪一个消息ID(哪个位置)开始消费,该位置之前的数据会被忽略,同时还用来初始化last_delivered_id这个变量。这个last_delivered_id一般来说就是最新消费的消息ID(这也是借用了 kafka commit offset 的概念)pending_ids:每个消费者内部的状态变量,作用是维护消费者的未确认的消息ID。
pending_ids记录了 当前已经被客户端读取,但是还没有 ack 的消息 。 目的是为了保证客户端至少消费了消息一次,而不会在网络传输的中途丢失而没有对消息进行处理。如果客户端没有 ack,那么这个变量里面的消息ID 就会越来越多,一旦某个消息被 ack,它就会对应开始减少。这个变量也被 Redis 官方称为 PEL (Pending Entries List)
基本命令
XADD:向Stream中添加消息。如果指定的Stream不存在,则会自动创建
1
2
3
4// MAXLEN maxlen:可选参数,用于限制Stream的最大长度。当Stream的长度达到maxlen时,旧的消息会被自动删除。
// ID id:可选参数,用于指定消息的ID。如果不指定该参数,Redis会自动生成一个唯一的ID。
// field1 value1 [field2 value2 ...]:消息的字段和值,消息的内容以key-value的形式存在。
XADD stream_name [MAXLEN maxlen] [ID id] field1 value1 [field2 value2 ...]XREAD:以阻塞/非阻塞方式获取Stream中的消息列表。
1
2
3
4// COUNT count:可选参数,用于指定一次读取的最大消息数量。如果不指定,默认为1。
// BLOCK milliseconds:也是一个可选参数,用于指定阻塞的时间(以毫秒为单位)。如果指定了阻塞时间,并且当前没有可消费的消息,客户端将在指定的时间内阻塞等待。如果不设置该参数或设置为0,则命令将立即返回,无论是否有可消费的消息。
// STREAMS key [key ...] ID [ID ...]:这部分指定了要消费的流(Streams)和对应的起始消息ID。可以一次指定多个流和对应的起始ID。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]XREADGROUP:从消费者组中读取消息,支持阻塞读取。
XACK:确认消费者已经成功处理了消息。
XGROUP:用于管理消费者组,包括创建、设置ID、销毁消费者组等操作。
XPENDING:查询消费者组中的待处理消息。